Git est loin d’être le seul système de contrôle de version open source. La concurrence existe aussi dans ce domaine dont voici trois représentants avec qui il faut aussi compter.
À l’origine, Git était un logiciel de contrôle de version développé pour gérer le code source du noyau Linux. Depuis, il est devenu l’outil par défaut pour gérer les bases de code source de pratiquement tous les projets open source, ainsi que de nombreux projets privés. Malgré sa popularité, Git suscite cependant plusieurs critiques. Son modèle d’organisation du code est jugé trop compliqué, son jeu de commandes déroutant, sans compter des interfaces graphiques et un front qui ne font que masquer une complexité sous-jacente desservant la résolution de problèmes. Git n’est pas non plus adapté à certains types de fichiers suivis dans les projets open source, comme les binaires volumineux et les structures de données étendues.
Les entreprises et utilisateurs préoccupés par ces soucis peuvent se demander quelles sont les alternatives possibles à Git. Il faut savoir qu’elles existent, et beaucoup d’entre elles prospèrent dans leur propre espace parce qu’elles proposent des fonctionnalités que ce dernier n’a pas. L’occasion est donc venue de se pencher sur trois des plus grandes alternatives à Git : Fossil, Mercurial et Subversion sur le plan des fonctionnalités, cas d’usage et les projets dans lesquels ils sont actuellement utilisés.
Fossil
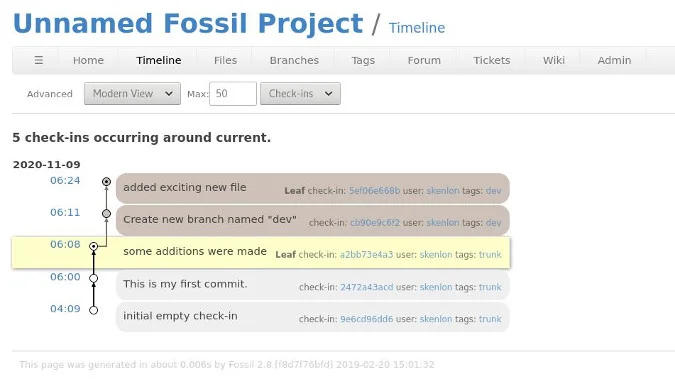
Dwayne Richard Hipp est surtout connu comme le créateur de SQLite, le système de base de données open source intégrable qui est l’un des logiciels les plus utilisés au monde. Mais cet illustre développeur n’utilise pas Git pour le contrôle des sources du projet SQLite. Il se sert plutôt de Fossil, un système qu’il a créé spécifiquement pour faciliter le développement de SQLite. La principale différence entre les deux solutions est que Fossil est un produit tout-en-un. Git se contente de suivre et d’annoter les modifications apportées à une base de code au moyen d’un système de fichiers virtuel. Fossil s’apparente lui davantage à Bitbucket, à savoir un système auto-hébergé qui ne se contente pas de suivre les modifications, mais intègre également le suivi des tickets et des bogues, des wikis, de la documentation et des discussions en direct pour un projet. Tout cela est soutenu par la base de données SQLite, et (comme SQLite lui-même) marche à partir d’un seul exécutable autonome avec une empreinte d’environ 8 Mo.
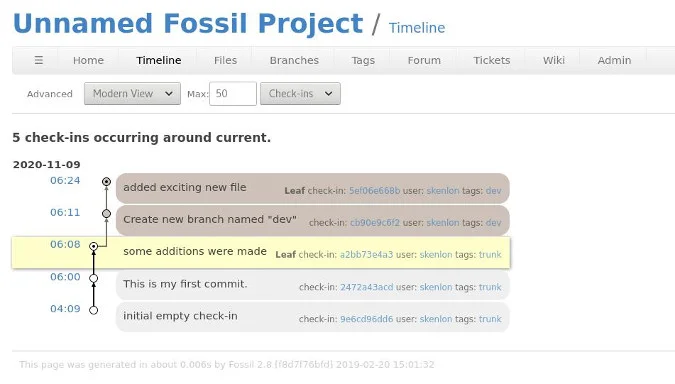
L’interface graphique de Fossil. (Crédit Photo : Red Hat)
Fossil utilise une structure de données similaire à celle de Git, mais là où celui-ci utilise le système de fichiers lui-même pour stocker les modifications, Fossil conserve tout dans une base de données SQLite. Les requêtes sur les modifications, telles que l’examen de toutes les modifications apportées à un fichier donné au fil du temps, ou les graphiques détaillés sur l’avancement d’un projet, peuvent être calculées rapidement, car elles se résument à des requêtes SQL. Les différences de conception et de comportement de Fossil le rendent, selon Dwayne Richard Hipp, plus adapté aux équipes plus petites et restreintes, comme celles qui travaillent sur SQLite et Fossil lui-même. Le service peut toujours fonctionner de manière décentralisée, mais la plupart des modifications à distance sont automatiquement synchronisées avec un dépôt principal, au lieu d’être développées séparément au fil du temps, puis réconciliées (ce que son fondateur appelle la philosophie « sync over push »). Le projet Tcl/Tk utilise Fossil, ainsi que quelques autres projets liés à Tcl. Dwayne Richard Hipp fournit des notes détaillées sur le passage de Git à Fossil, ou sur la synchronisation d’un projet entre les deux systèmes. A noter que les fonctionnalités spécifiques à Fossil, comme le wiki d’un projet, ne sont pas portées sur Git, du moins pas automatiquement.
Mercurial
En 2005, le système propriétaire de contrôle des sources BitKeeper a révoqué sa licence gratuite pour le noyau Linux. Deux systèmes de remplacement ont vu le jour dans le sillage de BitKeeper. L’un était Git, utilisé pour le noyau Linux (et plus tard, pour beaucoup d’autres choses). L’autre est Mercurial qui sert toujours par les développeurs travaillant pour Facebook, Mozilla, le W3C et le projet PyPy. D’un point de vue conceptuel, Mercurial et Git fonctionnent de la même manière. Ils utilisent tous deux un système graphique des modifications apportées à une base de code, et tout changement peut engendrer de nouveaux états. Mais le jeu de commandes Mercurial pour les cas d’utilisation courants est plus petit et plus facile à maîtriser – il s’agit de six ou sept commandes par rapport à la douzaine de commandes dans les scénarios Git. L’une des principales différences avec Git est le fonctionnement des branches dans l’arbre des sources. Lorsque l’on change de branche dans Git, le répertoire courant est réécrit pour refléter le contenu de la branche. Dans Mercurial, il existe plusieurs stratégies différentes pour créer des branches :
– Cloner le référentiel dans un autre répertoire et travailler sur celui-ci en tant que branche (il est facile de changer de branche mais plus long d’en créer une) ;
– Mettre en signet différents points d’un jeu de modifications et les utiliser comme base pour les modifications, ce qui ressemble beaucoup au comportement de Git ;
– Utiliser une « branche nommée » duquel le nom devient une partie permanente du jeu de modifications – utile dans la mesure où le nom est reflété dans toutes les modifications futures de cette branche, même si cela peut apporter de la complexité ;
– Créer des branches anonymes, non nommées, ce qui est pratique pour les modifications rapides, mais peut prêter à confusion en cas de manque d’explication appropriée de ce qui a été fait dans les notes de modification.
Différents clients Mercurial existent pour Windows et pour Mac. (Crédit Photo: DR)
Si l’utilisateur souhaite modifier le comportement de Git, il doit généralement utiliser d’autres programmes autonomes, conformément à la philosophie de la chaîne d’outils Linux selon laquelle « chaque programme fait une seule chose ». En revanche, Mercurial propose un mécanisme d’extension qui permet d’y intégrer du code tiers directement et d’étendre ses fonctionnalités. Celui-ci est livré avec un très grand nombre d’extensions, permettant à peu près tout de la comparaison des modifications avec des utilitaires externes à l’effacement de ce qui n’est pas activement modifié dans un répertoire donné. La fonctionnalité la plus utile est sans doute la possibilité de synchroniser un dépôt Mercurial avec un dépôt Git, ce qui est très utile si l’on fait passer une base de code de l’un à l’autre.
Subversion
Le projet Subversion de la Fondation Apache, également connu sous le nom de SVN, a vu le jour en 2000. Sa première version 1.0, en 2004, a légèrement précédé Git. Apache, FreeBSD et SourceForge sont quelques-uns des utilisateurs les plus connus de Subversion. Le projet GCC l’a utilisé jusqu’en 2019, mais a depuis migré vers Git.
La principale différence entre SVN et Git est qu’il est centralisé, ce qui signifie que le dépôt est stocké à un endroit unique et fixe. Les contributeurs ne font généralement pas de copies locales de la base de code, mais travaillent sur des branches du code dans la copie centralisée. Un administrateur peut définir des contrôles d’accès très granulaires sur un dépôt Subversion, de sorte que les contributions n’ont pas à être triées manuellement. La nature centralisée de SVN est à la fois un avantage et un inconvénient. C’est un écueil dans la mesure où si quelque chose arrive au dépôt central, il est donc préférable d’avoir un bon plan de sauvegarde. Le fait que chaque développeur conserve une copie du code rend les projets beaucoup plus résistants aux disques durs H.S. … ou aux administrateurs système vengeurs. Il est également difficile de tester l’ensemble de la base de code en une seule fois. Cela signifie également que les branches du code sont gérées de manière moins élégante – il s’agit essentiellement de répertoires physiques avec des copies discrètes du code, au lieu du modèle de système de fichiers virtuel de Git. Mais la disposition centralisée est un atout car elle rend le modèle conceptuel de SVN beaucoup plus simple, ce qui rend SVN plus facile à utiliser en général. Il y a moins d’étapes à connaître lorsqu’on travaille sur une base de code, même si ces étapes individuelles ont plus d’exigences. De plus, SVN gère mieux les gros fichiers binaires, car il utilise un algorithme de différenciation bien adapté à ce type de fichiers.
Comme pour Mercurial, il existe plusieurs clients Subversion mis en avant par différents éditeurs. (Crédit Photo: Aqua Data Studio)
Une autre différence majeure provient de la centralité de SVN. L’historique d’un dépôt est immuable. Git permet de modifier rétroactivement l’historique d’un dépôt, ce qui n’est pas le cas de SVN. Il s’agit d’une source unique de vérité pour un projet, ce qui est crucial si l’on veut exercer un contrôle strict sur les sources. GitHub lui-même a pris en charge les dépôts Subversion pendant un certain temps, mais il cessera progressivement de les prendre en charge à partir de janvier 2024. (GitLab et Bitbucket ne prennent pas en charge les référentiels Subversion ; pour les utiliser, il faut convertir manuellement un référentiel en Git).
En conclusion
Fossil offre une expérience tout-en-un qui s’apparente à une plateforme d’hébergement de code dans une boîte, avec ticketing et discussion, alors que Git se concentre exclusivement sur le suivi des modifications via une collection d’outils de philosophie Unix. Le mécanisme d’extension de Mercurial le rend nativement modifiable, alors que les comportements de Git seraient modifiés par des outils externes. Enfin, la centralisation de Subversion offre un modèle conceptuel plus simple et un contrôle plus étroit sur les sources, alors que Git propose des concepts complexes et une gestion décentralisée des fichiers.