
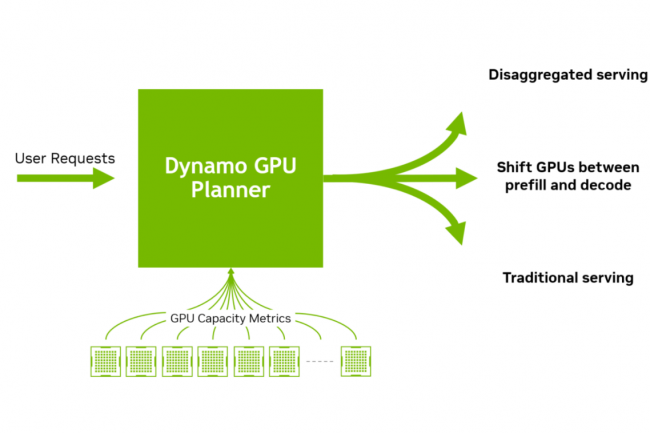
Selon le fournisseur de puces, son logiciel d’inférence open source, appelé à remplacer le serveur d’inférence Triton, augmente le débit et réduit le coût de génération de jetons LLM.
Présenté lors de la conférence GTC 2025 qui se tient du 17 au 20 mars à San José, en Californie, le logiciel d’inférence open oource Dynamo permettra aux entreprises d’augmenter le débit et de réduire les coûts lors de l’utilisation de grands modèles de langage sur les GPU Nvidia. « Orchestrer et coordonner efficacement les demandes d’inférence d’IA sur une grande flotte de GPU est crucial pour s’assurer que les usines d’IA (groupe de puces exécutant des charges de travail d’IA) fonctionnent au…
Il vous reste 92% de l’article à lire
Vous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?