
Actuellement en phase expérimentale, le framework Monarch donne la capacité aux développeurs Python de programmer des systèmes distribués comme s’il s’agissait d’une seule machine.
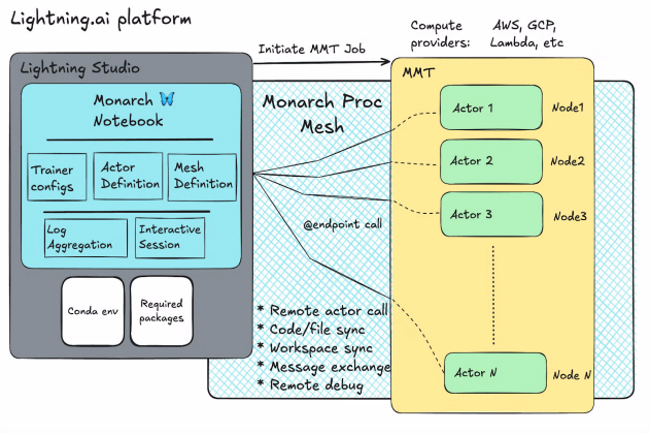
Dans le domaine de l’IA, le développement d’applications fait appel à des ressources distribuées sur plusieurs clusters. Le problème est qu’à a chaque modification, les développeurs sont obligés de réallouer, reconstruire et redéployer leurs flux de travail de A à Z. Pour remédier à cela, l’équipe en charge de Pytorch chez Meta et Lightning AI ont dévoilé un cadre open source nommé Monarch pour l’orchestration des clusters IA. Pour cela, « il associe une interface frontale basée sur Python, qui prend en charge l’intégration avec le code et les bibliothèques existantes telles que PyTorch, à une interface dorsale basée sur Rust, qui facilite les performances, l’évolutivité et la robustesse », explique les experts de Meta. Annoncé le 22 octobre, Monarch donne la possibilité aux développeurs de programmer en Python des systèmes distribués comme s’il s’agissait d’une seule machine. Il masque ainsi la complexité du calcul distribué, souligne l’équipe.
Le cadre organise les processus, les acteurs et les hôtes dans un tableau multidimensionnel évolutif qui peut être manipulé directement. Les utilisateurs peuvent opérer sur des tableaux entiers ou sur des portions, à l’aide d’API simples, Monarch gérant automatiquement la distribution et la vectorisation. Selon l’équipe PyTorch, les développeurs peuvent écrire du code comme si rien ne pouvait échouer. Mais lorsqu’un problème survient, Monarch réagit rapidement en arrêtant l’ensemble du programme. Plus tard, les utilisateurs peuvent ajouter une gestion des erreurs fine là où c’est nécessaire, afin de détecter et de corriger les défaillances.
Une dissociation du control et du data plane
Monarch sépare les messages du plan de contrôle des transferts du plan de données, ce qui favorise les transferts de mémoire directs de GPU à GPU à travers un cluster. Les commandes sont envoyées par un chemin tandis que les données transitent par un autre. Monarch s’intègre à PyTorch pour fournir des tenseurs qui sont répartis entre les clusters de GPU. « Les opérations sur les tenseurs semblent locales, mais elles sont exécutées sur de grands clusters distribués, Monarch gérant la complexité de la coordination entre des milliers de GPU », a précisé les spécialistes de Meta.
L’équipe PyTorch souligne qu’au stade expérimental actuel de développement de Monarch, les utilisateurs doivent s’attendre à des bogues, des fonctionnalités incomplètes et des API susceptibles de changer dans les versions futures. Les instructions d’installation de Monarch sont disponibles sur meta-pytorch.org.