Le fournisseur d’IA, Perplexity a publié en open source un outil nommé TransferEngine qui rend possible l’exécution de très grands LLM sur des GPU Nvidia H100 et H200. Pour cela, il accélère la communication entre GPU en favorisant l’interopérabilité entre les composants réseaux de Nvidia et AWS.
Perplexity a mis au point un logiciel open source qui résout deux problèmes coûteux pour les entreprises utilisant des systèmes d’IA : le fait d’être lié à un seul fournisseur de cloud et la nécessité d’acheter du matériel dernier cri pour faire tourner des modèles volumineux. Cet outil, appelé TransferEngine, donne la capacité à de très grands modèles de langage de communiquer à très grande vitesse entre des matériels de différents fournisseurs cloud. « Les dernières approches pour les LLM telles que l’inférence désagrégée, le routage de mélanges d’experts (mixture of experts, MoE) et le réglage fin asynchrone par renforcement, nécessitent une communication point à point flexible », expliquent des chercheurs de Perplexity.
Dans ce cadre, ils on trouvé un moyen pour les entreprises d’exécuter des modèles à plusieurs milliers de milliards de paramètres, tels que DeepSeek V3 qui contient 671 milliards de paramètres et Kimi K2 (de la start-up chinoise Moonshot AI) affichant 1 trillion de paramètres, par exemple sur « d’anciens » accélérateurs Nvidia comme le H200 (novembre 2024) voire même le H100 (mars 2022). Ils indiquent avoir également mis TransferEngine en open source sur GitHub.
Le piège du verrouillage fournisseur
Pour eux la problématique provient du fait que « les implémentations existantes sont verrouillées sur des contrôleurs d’interface réseau (NIC) spécifiques, ce qui entrave l’intégration dans les moteurs d’inférence et la portabilité entre les fournisseurs de matériel ». Ils citent l’exemple des incompatibilités entre les solutions réseau de Nvidia Connect-X et le protocole propriétaire Elastic Fabric Adapater (EFA) d’AWS. Les autres fournisseurs ont aussi leur propre adaptateur réseau comme Cloud eRDMA pour Alibaba et Falcon pour Google. Les entreprises sont donc obliger de s’engager dans l’écosystème d’un seul fournisseur ou le cas échéant d’accepter des performances nettement plus lentes. Le problème est particulièrement aigu avec les approches MoE, assure Perplexity.
Pour pallier ce problème, il serait possible de s’appuyer sur des systèmes GB200 NVL72 de Nvidia à 36 processeurs Grace et 72 GPU Blackwell reliés entre eux via NVLink-C2C (900 Go/s). Mais ceux-ci coûtent des millions de dollars, font face à des pénuries d’approvisionnement extrêmes, et ne sont pas disponibles partout, notent les chercheurs. En revanche, les systèmes H100 et H200 sont abondants et relativement bon marché. Le hic : l’exécution de modèles volumineux sur des systèmes plus anciens a toujours entraîné des pertes de performances considérables. « Il n’existe aucune solution viable entre différents fournisseurs pour l’inférence LLM », écrivent les experts, soulignant que les bibliothèques existantes ne prennent pas du tout en charge AWS ou souffrent d’une grave dégradation des performances sur le matériel Amazon. TransferEngine vise à changer cela. Il « met en place une communication point à point portable pour les architectures LLM modernes, évitant ainsi la dépendance vis-à-vis d’un fournisseur tout en complétant les bibliothèques collectives pour les déploiements natifs dans le cloud », précisent les spécialistes de Perplexity.
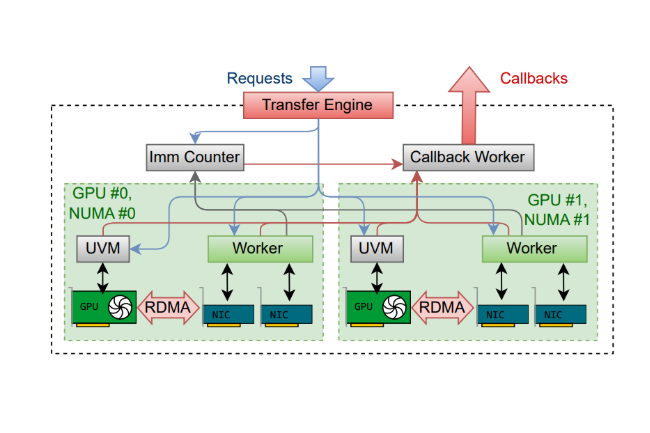
Comment fonctionne TransferEngine
Selon l’article, TransferEngine agit comme un « traducteur universel pour la communication entre GPU ». Il crée une interface commune qui fonctionne sur différents composants réseau en identifiant les fonctionnalités de base partagées par divers systèmes. TransferEngine s’appuie sur une approche RDMA (remote firect memory access) permettant aux systèmes de transférer des données directement entre les cartes graphiques sans passer par les processeurs centraux. On peut comparer cela à une voie rapide dédiée entre les puces. La mise en œuvre de Perplexity a atteint un débit de 400 gigabits par seconde sur Nvidia ConnectX-7 et EFA d’AWS.
L’outil prend également en charge l’utilisation de plusieurs cartes réseau par GPU, ce qui permet d’agréger la bande passante pour une communication encore plus rapide. « Nous abordons la question de la portabilité en tirant parti des fonctionnalités communes à l’ensemble du matériel RDMA hétérogène », explique l’article, soulignant que cette approche fonctionne en créant « une abstraction fiable sans garantie d’ordre » sur les protocoles sous-jacents.
Déjà fonctionnel en environnements de production
Cette technologie n’est pas seulement théorique. Selon l’entreprise, Perplexity utilise TransferEngine en production pour alimenter son moteur de recherche IA. L’entreprise l’a déployé sur trois systèmes critiques. Pour l’inférence désagrégée, l’outil gère le transfert à grande vitesse des données mises en cache entre les serveurs, ce qui apporte aux entreprises d’adapter leurs services d’IA de manière dynamique. La bibliothèque alimente également le système d’apprentissage par renforcement du fournisseur, en mettant à jour les poids de modèles à plusieurs trillions de paramètres en seulement 1,3 seconde, selon les chercheurs. Mais le plus important est peut-être que Perplexity a mis en œuvre TransferEngine pour le routage MoE, créant ainsi un trafic réseau bien plus important que les modèles traditionnels.
DeepSeek a créé son propre framework DeepEP pour gérer cela, mais il ne fonctionnait que sur le matériel Nvidia ConnectX, selon l’article. L’outil open source a égalé les performances de DeepEP sur ConnectX-7, ont déclaré les chercheurs. Plus important encore, ils ont déclaré qu’il avait atteint une « latence de pointe » sur les composants Nvidia tout en créant « la première implémentation viable compatible avec AWS EFA ». En testant DeepSeek V3 et Kimi K2 sur des instances AWS H200, Perplexity a constaté des gains de performances substantiels lors de la distribution de modèles sur plusieurs nœuds, en particulier avec des lots de taille moyenne, le point idéal pour la production.
Le pari de l’open source
La décision de Perplexity d’ouvrir le code source de TransferEngine contraste fortement avec celle de concurrents tels qu’OpenAI et Anthropic, qui gardent leurs implémentations techniques propriétaires. La société a publié la bibliothèque complète, y compris le code, les liaisons Python et les outils de benchmarking, sous une licence ouverte.
Cette initiative reflète la stratégie de Meta avec PyTorch : ouvrir l’accès à un outil essentiel, contribuer à établir une norme industrielle et tirer parti des contributions de la communauté. Perplexity a déclaré qu’elle continuait à optimiser la technologie pour AWS, à la suite des mises à jour des bibliothèques réseau d’Amazon visant à réduire davantage la latence.