
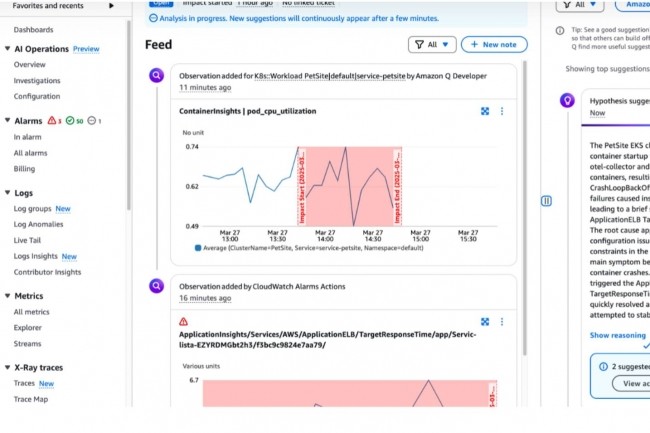
Le fournisseur cloud américain ajoute une fonction d’alertes automatisées à son assistant GenAI dans les investigations CloudWatch. Objectif : fournir une analyse post-mortem liée à des incidents pour améliorer leur compréhension et accélérer le temps de rétablissement.
En réponse à une panne majeure survenue lundi et résolue non sans mal, AWS soigne ses clients et a ajouté une fonction automatisée de génération d’incidents à CloudWatch. Ce service de surveillance et d’observabilité aide les entreprises à obtenir des informations sur la santé opérationnelle de leurs instances cloud et à réagir à tout changement en vue de leur optimisation. Cet ajout est intégré à l’assistant GenAI embarqué dans le module investigation de CloudWatch et doit aider les entreprises à créer rapidement un rapport d’analyse complet après un incident, mieux comprendre ses raisons et prendre des mesures adéquates en vue de limiter leur impact.
« La fonctionnalité […] recueille et corrèle automatiquement vos données télémétriques, ainsi que vos saisies et toutes les mesures prises au cours d’une enquête, et génère un rapport d’incident simplifié », indique AWS dans un billet de blog. Ces rapports comprendront des résumés explicites, une chronologie des événements, des évaluations d’impact et des recommandations concrètes, aidant ainsi les entreprises à identifier des tendances, à mettre en œuvre des mesures préventives et à améliorer continuellement leur posture opérationnelle, a ajouté AWS. Charlie Dai, analyste principal chez Forrester, a déclaré que cette fonction est un moyen pour le fournisseur de regagner la confiance de ses clients, en particulier après la panne, qui a ensuite été attribuée à une panne de résolution DNS du point de terminaison de l’API DynamoDB.
Des rapports post-mortem utiles mais pas suffisants
Ces rapports peuvent aider les entreprises à améliorer leur résilience, poursuit M. Dai. Il a toutefois souligné que la société pourrait mieux aider ses clients à minimiser les temps d’arrêt et les risques business en promouvant des architectures multirégionales, des stratégies de basculement actif-actif et DNS redondantes. Il a ajouté que si les rapports contribuent à accélérer l’analyse post-mortem, ils sont loin d’être suffisants et que seule l’amélioration continue des produits, associée à l’optimisation des pratiques, peut aider à minimiser les risques systémiques.
Pour profiter de cette dernière fonction, les utilisateurs doivent poser des questions à l’assistant GenAI dans la fonction investigation de CloudWatch sur les problèmes de performance d’un service particulier ou sur la raison de son indisponibilité. Une fois ces informations demandées, le chatbot analyse le système afin de trouver les données télémétriques susceptibles d’être pertinentes pour la situation, puis génère des hypothèses basées sur ses conclusions. Une fois les hypothèses acceptées par l’utilisateur, il est possible de demander à l’assistant de générer un rapport d’incident, comme l’indique AWS dans sa documentation. Actuellement, la fonctionnalité de génération de rapports d’incident est disponible dans les régions suivantes : Est des États-Unis (Virginie du Nord), Est des États-Unis (Ohio), Ouest des États-Unis (Oregon), Asie-Pacifique (Hong Kong), Asie-Pacifique (Mumbai), Asie-Pacifique (Singapour), Asie-Pacifique (Sydney), Asie-Pacifique (Tokyo), Europe (Francfort), Europe (Irlande), Europe (Espagne) et Europe (Stockholm).
Les fournisseurs d’observabilité à l’affût
La panne d’AWS a éveillé l’attention d’autres fournisseurs de solutions d’observabilité. Datadog a par exemple lancé un site web gratuit offrant aux entreprises de surveiller l’état des services de plusieurs fournisseurs de services cloud. Cependant, ce n’est pas le seul du genre : des sites similaires, en particulier des agrégateurs de pages d’état et des trackers basés sur les rapports des utilisateurs, tels que Updownradar.com, IsTheServiceDown.com et Downdetector, fournissent déjà des informations sur les pannes.
Presque tous les fournisseurs de services cloud, tels que Google, Microsoft et Alibaba, proposent également une page ou un service d’informations sur l’état des services : Azure Service Health fournit des alertes personnalisées, des rapports sur les causes profondes et des conseils en cas d’incident, Google Cloud des tableaux de bord Service Health et des alertes personnalisées pour les ressources concernées, et Alibaba Cloud un service de réponse aux incidents pour la gestion des urgences et la planification post-incident.