
Le dernier système d’apprentissage par renforcement Spice de Meta permet aux grands modèles de langage de s’améliorer en utilisant des données du monde réel plutôt que des ensembles de formation sélectionnés.
Appelé Spice (Self-Play in Corpus Environments), ce framework d’apprentissage par renforcement dévoilé par les chercheurs de Meta pousse les grands modèles de langage (LLM) à améliorer leurs capacités de raisonnement sans supervision humaine. Développé en collaboration avec l’Université nationale de Singapour, Spice entraine un modèle unique à agir à la fois comme un challenger, qui génère des problèmes complexes basés sur des documents, et comme un raisonneur, qui les résout. En fondant le processus d’apprentissage sur des corpus de textes réels plutôt que sur des données synthétiques, le système évite les boucles d’hallucination qui ont affecté les méthodes d’auto-apprentissage précédentes. En moyenne, dans les tests de référence en mathématiques et en raisonnement général, le modèle parvient à s’améliorer de près de 10 %. Cette approche est présentée par les chercheurs comme un « changement de paradigme » vers des systèmes d’IA capables de s’améliorer eux-mêmes grâce à l’interaction avec les vastes connaissances vérifiables intégrées dans les documents web plutôt qu’avec des ensembles de données statiques sélectionnés par des humains.
Une IA difficile à mettre en œuvre
L’idée d’une IA auto-améliorée a commencé à prendre forme avec le développement des LLM capables de raisonner. Cependant, la plupart des méthodes existantes se heurtent à des obstacles fondamentaux après quelques progrès initiaux. « Sans ancrage externe, les modèles atteignent inévitablement un plateau ou s’effondrent en raison de deux problèmes critiques », ont déclaré les chercheurs dans leur article. « D’abord, l’amplification des hallucinations, où les erreurs factuelles dans les questions et les réponses générées s’aggravent à mesure que les modèles s’entraînent sur leurs propres données synthétiques non vérifiables, et ensuite, la symétrie de l’information, où le générateur de problèmes et le solveur partagent la même base de connaissances, ce qui empêche tout véritable défi et conduit à des modèles plus simples et plus répétitifs. »
Même les nouvelles techniques qui tentent de maintenir la diversité des données d’entraînement, telles que la synthèse variationnelle, se heurtent encore à des limites. Elles ne peuvent fonctionner qu’avec ce qui a déjà été capturé pendant le pré-entraînement, remixant essentiellement les mêmes informations de manière nouvelle. »
Ce qui rend Spice efficace
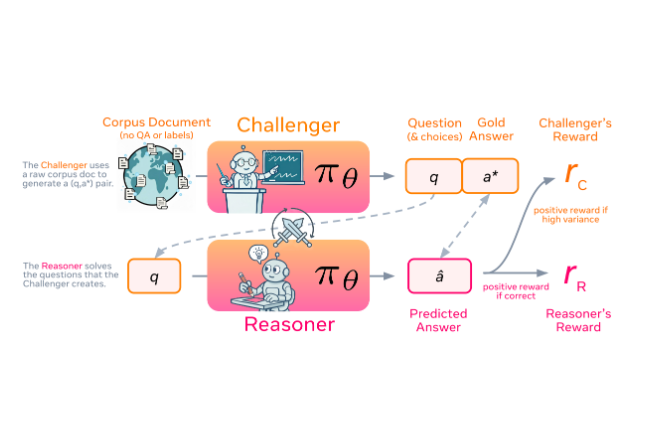
Spice repose sur le concept selon lequel un seul LLM assume deux rôles alternatifs, l’un qui crée des défis et l’autre qui tente de les résoudre. Dans une phase, le modèle agit comme le Challenger, celui qui tire des informations d’un vaste corpus de documents pour générer des questions complexes fondées sur ces documents. Dans la phase suivante, il change de rôle pour devenir le Reasoner, celui qui essaye de répondre à ces questions sans voir le matériel source. Le challenger obtient des récompenses plus importantes lorsqu’il crée des problèmes qui se situent à la limite de ce que le raisonneur peut gérer, rendant les tâches difficiles mais qu’il est toujours possible de résoudre. Le raisonneur est récompensé pour avoir produit des réponses correctes.
Ce processus itératif, étayé par des données réelles, permet au système de continuer à découvrir de nouveaux défis et d’améliorer sa capacité à les résoudre sans supervision humaine. Cette approche supprime la vérification qui limitait auparavant la recherche à des domaines spécialisés comme les mathématiques et le codage. Les réponses étant basées sur des documents réels, le système peut les vérifier à l’aide de sources factuelles plutôt que de s’appuyer sur des données synthétiques ou supposées.
Des performances de raisonnement améliorées
Lorsqu’ils ont testé différents LLM, les chercheurs ont constaté que Spice présentait des améliorations claires et constantes dans les performances de raisonnement. Sur le modèle Qwen3 4B, les performances sont passées de 35,8 % à 44,9 %, tandis que sur le modèle 8B, plus grand, elles sont passées de 43,0 % à 48,7 %. Un impact plus fort a été observé dans les modèles OctoThinker, avec des améliorations de 14,7 % à 25,2 % sur la version 3B et de 20,5 % à 32,4 % sur la version 8B. « La dynamique antagoniste entre Challenger et Reasoner crée un programme d’apprentissage automatique : le taux de réussite fixe de Reasoner diminue de 55 % à 35 % à mesure qu’il apprend à générer des problèmes de plus en plus difficiles, tandis que le taux de réussite fixe de Challenger augmente de 55 % à 85 %, ce qui indique une coévolution réussie des deux rôles », indique l’étude.
Les chercheurs ont également constaté qu’il était essentiel d’ancrer le processus de formation dans des documents réels pour obtenir une amélioration durable. Les modèles entraînés sans cette référence externe ont rapidement atteint leurs limites et ont cessé de s’améliorer. Mais lorsque Spice s’est appuyé sur des textes réels, il a continué à progresser régulièrement, utilisant de nouveaux documents pour générer des défis nouveaux et plus complexes tout au long de l’entraînement.
Implications de l’étude
En utilisant de grandes collections de documents comme sources externes de connaissances, Spice aide les modèles à s’améliorer au lieu de stagner sur leurs propres données. Selon les analystes du secteur, ces frameworks pourraient à terme influencer la manière dont les entreprises entraînent les modèles d’IA spécifiques à un domaine, mais leur adoption s’accompagnera de nouvelles responsabilités. « Spice ouvre des possibilités pour l’IA adaptative, mais les entreprises ne peuvent pas se permettre de le mettre en place et de l’oublier », a souligné Tulika Sheel, vice-présidente senior chez Kadence International. « Les systèmes auto-améliorants ont besoin de mécanismes d’auto-vérification. La supervision humaine, les pistes d’audit et les garde-fous de conformité doivent rester au premier plan. » Mme Sheel fait remarquer que si la configuration Challenger-Reasoner pouvait, en théorie, être reproduite avec des données d’entreprise comme des documents financiers ou juridiques, elle nécessiterait « une infrastructure solide, des ensembles de données propres et une forte attention portée à la transparence. » Celle-ci met également en garde sur les risques introduits par les boucles d’apprentissage autonomes, notamment l’amplification des biais et la dérive de la conformité. « Spice rapproche l’IA de l’autosuffisance, mais l’autonomie sans responsabilité est dangereuse », a-t-elle déclaré.
Anish Nath, directeur des pratiques chez Everest Group, pense que les entreprises tireraient davantage profit de frameworks tels que Spice en les considérant comme une capacité de formation et non comme une autonomie dans la production. Il suggère de lancer des tests autonomes dans des sandbox avec des versions contrôlées, en commençant par des workflows internes à faible risque, puis de passer à des processus critiques à mesure que les preuves s’accumulent. Il recommande également « de mettre en place des garde-fous, par exemple des sorties contraintes par des schémas, un moteur de politiques, des listes blanches d’outils à faibles privilèges, une détection des dérives/anomalies, des actions signées et des pistes d’audit, des boutons de retour en arrière/d’arrêt d’urgence et des approbations humaines pour les actions à fort impact. » M. Nath ajoute que les données d’entraînement auto-générées orientent vers des boucles de développement autonomes, mais il met en garde contre des risques d’effondrement des modèles, d’empoisonnement des données et de dérives non suivies. « Ces risques peuvent être atténués grâce à des modèles d’évaluation indépendants, à un suivi de la provenance, à des ensembles de données versionnés et à des contrôles humains pour les mises à niveau des capacités », a-t-il expliqué, insistant sur le fait que « les améliorations doivent rester contrôlées, vérifiables et conformes. »