
Alors que les infrastructures de calcul intensif exigent des performances de plus en plus pointues, la Fondation Daos promeut un système de stockage open source sans équivalent, conçu pour répondre aux besoins de l’IA, de l’analyse de données et des workflows scientifiques.
20 microsecondes : c’est le temps moyen mesuré pour accéder à un octet de données via le système Daos (Distributed Asynchronous Object Storage) dans certaines configurations. En matière de stockage, chaque microseconde compte — particulièrement dans les centres de calcul de nouvelle génération où se jouent des simulations scientifiques massives et des entraînements de modèles IA complexes. Cette exigence de performance, la Fondation Daos entend y répondre avec une solution pensée dès le départ pour l’exascale. Fondée en 2023, la Fondation Daos – sous l’égide de la puissante Fondation Linux – a pour mission de garantir la neutralité du projet vis-à-vis des industriels qui y contribuent — Intel, HPE, Google, Vdura ou encore Argonne. Tous collaborent au sein d’un comité technique ouvert, sans que l’un d’entre eux ne domine les orientations stratégiques. « Notre ambition est de maintenir Daos comme un projet communautaire robuste, même en cas de changement de stratégie chez l’un des membres », nous a expliqué Johann Lombardi, président du comité technique de la Fondation Daos, lors d’un IT Press Tour à Londres début avril. Le projet est distribué sous licence BSD+Patent, choisie pour maximiser l’adoption tout en offrant une protection sur les brevets intégrés au code.
Une architecture repensée depuis l’utilisateur jusqu’au lecteur
Développé à l’origine par Intel en 2012 pour ses composant mémoire Optane (voir encadré ci-dessous), Daos se distingue par une approche radicalement différente de l’architecture traditionnelle. Le système repose sur une exécution entièrement dans l’espace client, éliminant les couches de traitement dans le noyau, historiquement adaptées aux disques durs. Cela permet un traitement I/O non bloquant, appuyé sur un modèle transactionnel distribué. Parmi les principes fondamentaux du design : l’absence de serveur centralisé de métadonnées, pas de table globale d’objets, ni de verrouillage côté client. L’ensemble repose sur un contrôle de concurrence multiversion (MVCC), inspiré du monde des bases de données, qui permet d’éliminer les conflits d’accès sans verrou. « Nous parions sur le fait que, dans 99,9 % des cas, il n’y a pas de conflit », explique Johann Lombardi. « Cela nous permet d’éviter les coûts inhérents aux verrous, tout en offrant une meilleure évolutivité. »
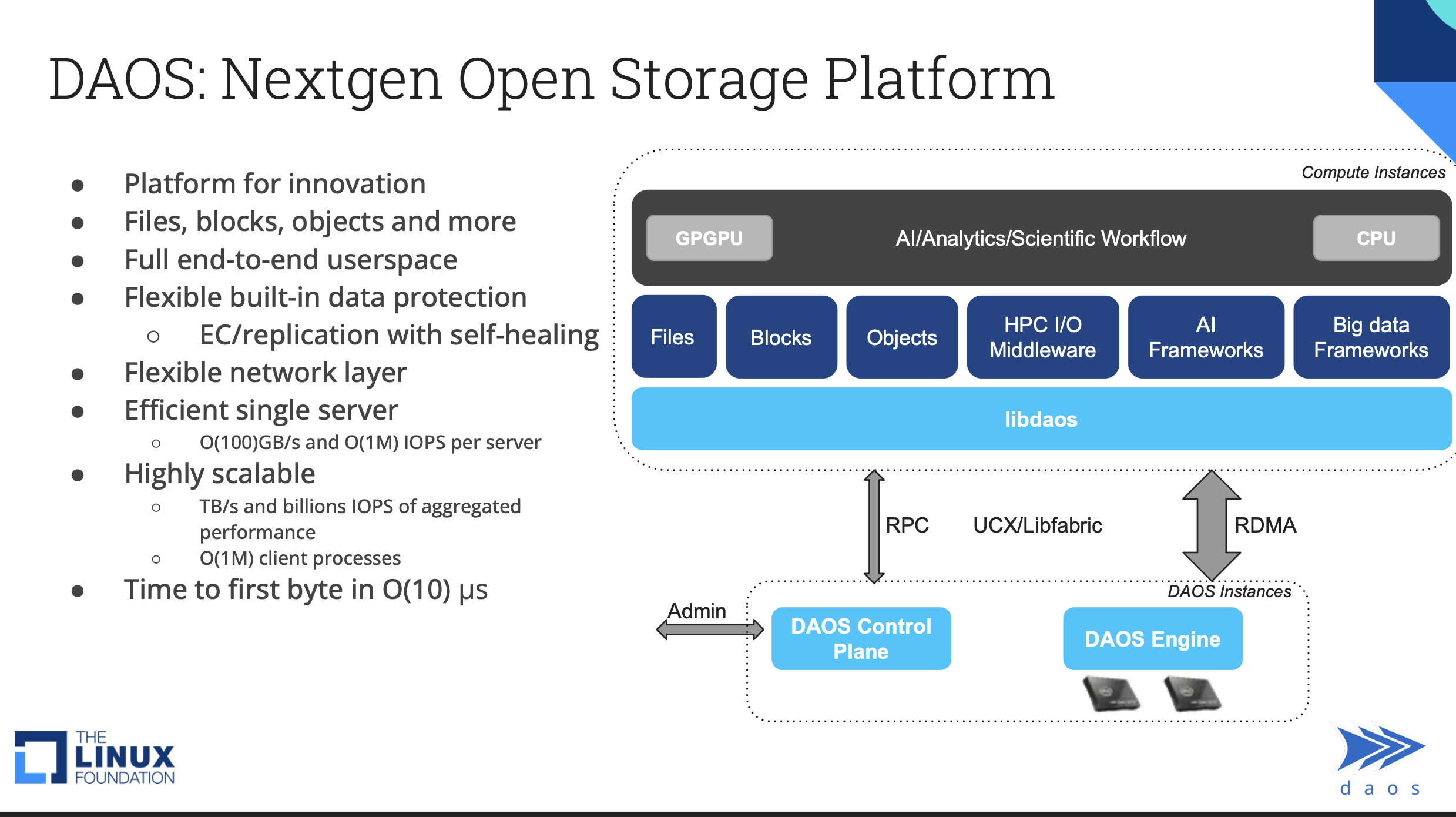
Daos travaille avec des systèmes fichiers, bloc et objet.
Flexibilité technologique et compatibilité applicative
La structure modulaire de Daos le rend compatible avec différents types de données : fichiers Posix, objet, bloc, ou encore jeux de données structurés via des interfaces Python ou HDF5. Cela en fait une plateforme d’intégration possible pour une grande variété d’usages, du calcul haute performance à l’analyse distribuée en environnement cloud. Daos est également conçu pour fonctionner avec ou sans mémoire persistante (PMEM). Suite à l’arrêt de la technologie Optane par Intel, l’équipe a mis au point un mode « pmem-less » performant, en utilisant une structure de type write-ahead log pour assurer la persistance sur SSD classiques. « La transition vers le mode sans mémoire persistante n’a nécessité que des modifications localisées dans le moteur », précise Johann Lombardi. « Toute la pile logicielle au-dessus reste inchangée, ce qui démontre la robustesse de notre architecture. »
Performance et cas d’usage en production
Daos a été sélectionné pour équiper HPE Aurora, le supercalculateur exascale du Laboratoire national d’Argonne. Avec une capacité utile de près de 250 pétaoctets et un débit de plus de 20 téraoctets par seconde, le système y gère plus de 177 milliards de fichiers. Les performances, validées via les benchmarks IO500, placent Daos en tête du classement dans plusieurs configurations. Cette flexibilité se traduit aussi par une approche multi-locataires. Un même cluster peut héberger des pools de stockage isolés, chacun avec des performances et des politiques d’accès différenciées. Ce modèle permet à plusieurs projets de coexister en toute sécurité et d’optimiser l’utilisation des ressources matérielles.
Loin des effets d’annonce, Daos incarne une refonte en profondeur du paradigme de stockage pour le calcul à grande échelle. Sa structure modulaire, sa performance prouvée, et son ouverture en font un candidat sérieux pour les architectures exascale et les plateformes d’IA avancées. Reste à voir si cette approche convaincra au-delà des early adopters et si d’autres industriels rejoindront une fondation qui revendique, avant tout, la stabilité dans un monde technologique en constante évolution.