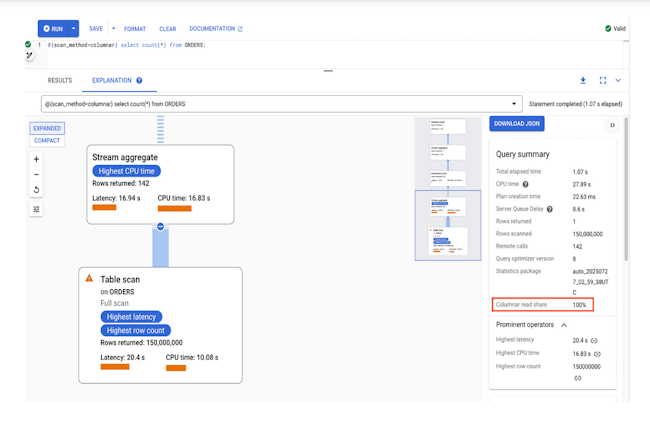
Disponible en aperçu, le moteur en colonnes pour Spanner va simplifier l’analyse en temps réel des données transactionnelles, en réduisant la complexité ETL et en améliorant les performances.
En parallèle du lancement d’agents IA pour les métiers de la donnée, Google Cloud a apporté des mises à jour pour son service managé de bases de données Spanner. Il intègre notamment un moteur en colonnes pour exécuter des requêtes analytiques complexes sur des données transactionnelles en temps réel pour une meilleure prise de décision. Actuellement en mode preview, cette capacité résout un problème typique auquel sont confrontées la plupart des entreprises : exploiter une base de données capable de gérer les données de transactions (OLTP) et le traitement analytique (OLAP) sans augmenter les coûts opérationnels.
Si les bases de données pour les charges de travail OLTP, comme Spanner, excellent dans les transactions rapides et à haut volume utilisant un stockage orienté lignes, les bases de données pour les workload OLAP, telles qu’Amazon Redshift, BigQuery et Snowflake, nécessitent des analyses et des agrégations approfondies sur de vastes ensembles de données, généralement gérées par des entrepôts de données en colonnes distincts. Souvent, pour combler le fossé entre ces deux types de bases de données, les entreprises doivent transférer périodiquement les données de l’une à l’autre, ce qui entraîne des données obsolètes, des pipelines ETL complexes et une augmentation des coûts opérationnels.
L’apport essentiel du stockage en colonnes
Grâce à l’utilisation du stockage en colonnes, le moteur de Spanner combine le traitement transactionnel et analytique sans augmenter la charge opérationnelle. Comme l’indique Google, les données sont conservées dans un format en colonnes parallèlement au stockage existant orienté lignes. Le stockage en colonnes présente plusieurs avantages pour les charges de travail analytiques, notamment il réduit le temps nécessaire aux opérations d’entrée-sortie (E/S), améliore la compression et propose un balayage plus efficace des colonnes.
« Souvent, les requêtes analytiques n’accèdent qu’à quelques colonnes à la fois. Avec le stockage en colonnes, seules les colonnes pertinentes doivent être lues à partir du lecteur, ce qui réduit considérablement les opérations d’E/S », a expliqué Google Cloud dans un blog. Il « améliore également les performances des analyses, en permettant le traitement en masse de valeurs consécutives », a ajouté le fournisseur. De plus, afin d’améliorer les performances et l’utilisation du processeur, Google a intégré le moteur en colonnes aux capacités d’exécution vectorisées existantes de Spanner. « Alors que les moteurs de requête traditionnels traitent les données ligne par ligne, un moteur vectorisé traite les données par lots (vecteurs) de lignes », a précisé Google, ajoutant que ce mode de fonctionnement optimise l’accès à la mémoire.
Faciliter l’intégration avec BigQuery
Selon l’hyperscaler, le moteur en colonnes devrait également aider les entreprises à intégrer plus facilement Spanner à BigQuery. En règle générale, si une entreprise souhaite effectuer des analyses de données complexes et volumineuses dans BigQuery à partir de données en temps réel stockées dans Spanner, l’opération prendrait beaucoup de temps pour gérer les pipelines de données et imposerait une charge supplémentaire aux systèmes principaux de Spanner. « En revanche, le moteur en colonnes, associé à la fonctionnalité Data Boost de Spanner, peut traiter ces requêtes complexes beaucoup plus rapidement sans ralentir les transactions quotidiennes », a affirmé la société. « Les entreprises peuvent bénéficier du meilleur des deux mondes : la cohérence transactionnelle de Spanner et les capacités analytiques de BigQuery, sans avoir besoin de pipelines ETL complexes pour dupliquer les données », a fait valoir le fournisseur de cloud.
Cependant, Google n’est pas le seul fournisseur de bases de données et d’entrepôts de données à chercher à offrir à la fois OLTP et OLAP. AWS a combiné les deux capacités dans Aurora et Redshift, Microsoft propose Azure Cosmos DB avec des fonctionnalités analytiques intégrées et Snowflake a aussi ajouté des charges de travail transactionnelles à sa plateforme axée sur l’analyse. Dans le camp open source, des bases de données telles qu’Apache Doris, ClickHouse et ColumnStore de MariaDB s’orientent également vers le traitement hybride. Les entreprises peuvent aussi choisir PostgreSQL via des extensions telles que Citus et Timescale pour le traitement hybride. Enfin, AlloyDB de Google, basé sur PostgreSQL, offre aussi un moteur en colonnes pour le traitement hybride.