
Récemment, Google a actualisé l’API de son assistant IA avec le support du LLM Gemini 3 lancé en novembre dernier. Une intégration impliquant plusieurs évolutions.
Toilettage d’automne pour l’API Gemini avec plusieurs évolutions à la clé. Ainsi, on peut citer des commandes plus simples pour la réflexion, un contrôle plus granulaire du traitement multimodal de la vision et des « signatures de pensée » pour améliorer l’appel des fonctions et la génération d’images. Les détails sur ces améliorations ont été publiés le 25 novembre dans un blog. Toutes sont conçues pour prendre en charge le raisonnement, le codage autonome, la compréhension multimodale et les capacités agentiques de Gemini 3. Comme l’a déclaré Google, « ces améliorations de l’API Gemini doivent donner aux utilisateurs plus de contrôle sur la façon dont le modèle raisonne et traite les médias, ainsi que sur la façon dont il interagit avec le monde « extérieur » ».
Parmi les améliorations apportées à l’API, on trouve des paramètres simplifiés pour le contrôle de la réflexion, via un paramètre appelé thinking_level ou « signatures de pensées ». Ce paramètre contrôle la profondeur maximale du raisonnement interne du modèle avant qu’une réponse ne soit produite. Le paramètre thinking_level peut être réglé sur plusieurs degrés de réflexion : « élevé » pour les tâches complexes telles que l’analyse stratégique des activités, et « faible » pour les applications sensibles à la latence et au coût. Un niveau « medium » sera bientôt ajouté.
Un effort sur le multimodal
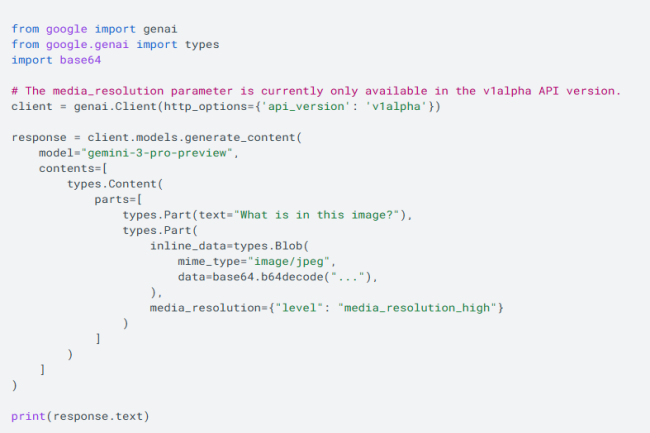
L’API Gemini offre désormais un contrôle plus précis sur le traitement multimodal de la vision, grâce à un paramètre media_resolution qui permet de configurer le nombre de jetons utilisés pour les entrées d’images, de vidéos et de documents. Les développeurs peuvent ainsi trouver le juste équilibre entre fidélité visuelle et utilisation des jetons. La résolution peut être définie à l’aide des paramètres media_resolution_low, medium ou high. Selon Google, une résolution plus élevée améliore la capacité du modèle à lire les textes fins ou à identifier les petits détails.
À partir de Gemini 3, l’API de l’assistant réintroduit également les signatures de pensée ou thought signatures, afin d’améliorer l’appel des fonctions et la génération d’images. Les signatures de pensée sont des représentations cryptées du processus de pensée interne du modèle. En renvoyant ces signatures au modèle lors des appels API suivants, les développeurs peuvent s’assurer que Gemini 3 conserve sa chaîne de raisonnement tout au long d’une conversation. « Cela est important pour les workflows complexes et en plusieurs étapes où il est tout aussi important de préserver le « pourquoi » d’une décision que la décision elle-même », a expliqué Google. De plus, les développeurs peuvent désormais combiner des sorties structurées avec des outils hébergés par Gemini, notamment Grounding avec Search et URL Context. « La combinaison de sorties structurées est particulièrement puissante pour créer des agents qui doivent récupérer des informations en direct sur le Web ou sur des pages spécifiques et extraire les données au format JSON pour des tâches en aval », a indiqué Google, précisant qu’il avait mis à jour la tarification de Grounding avec Search afin de mieux prendre en charge les flux de travail des agents. Le modèle de tarification passe d’un tarif forfaitaire de 35 $ HT pour 1000 requêtes à un tarif basé sur l’usage de 14 $ HT pour 1000 requêtes de recherche.