
Intégré à M365 Copilot pour améliorer la collecte et l’analyse de sources, l’agent Recherche se dote de deux capacités multi-modèles supplémentaires, Critique et Council. Avec à la clé des de meilleures performances pour comparer, vérifier et nuancer les analyses et fournir des informations plus fiables, précises et mieux structurées.
Face à la demande croissante des entreprises pour des outils IA capables de produire des analyses plus précises et nuancées, Microsoft étend les capacités de son agent Recherche – reposant sur les modèles GPT d’OpenAI et Claude d’Anthropic – conçu pour un raisonnement plus approfondi des tâches et aider à collecter, synthétiser et analyser plus efficacement des informations. L’objectif de cette extension est d’améliorer la qualité des contenus générés par l’IA et apporter aux utilisateurs des mécanismes plus fiables pour la prise de décision. La dernière mise à jour annoncée par le fournisseur introduit deux dernières capacités multi-modèles : Critique et Council .
Critique, qui utilise une combinaison de LLM dont ceux d’Anthropic et d’OpenAI, optimise l’exploration approfondie et la synthèse structurée ainsi que la validation des affirmations. « Critique incite Recherche à identifier les angles d’analyse manquants, à combler les lacunes dans la couverture, à affiner ses formulations et à produire des réponses mieux structurées et dotées d’un fil narratif plus clair », explique Gaurav Anand, vice-président corporate Ingénierie de Microsoft. A noter qu’il sera utilisé par défaut dans Recherche lorsque l’option auto est choisie dans le sélecteur de modèles. Council quant à lui compare les résultats obtenus par plusieurs modèles et est disponible lorsque l’option « Model Council » est cochée dans le sélecteur de modèles de Recherche. « Council exécute simultanément un LLM Anthropic et un LLM OpenAI, chaque modèle produisant un rapport complet et autonome qui met en évidence des faits, des citations et des cadres analytiques que l’autre pourrait négliger ou pondérer différemment. Une fois les deux rapports générés, un modèle juge dédié évalue les rapports afin de créer un résumé condensé des principales conclusions et de mettre en évidence les points sur lesquels les modèles s’accordent ou divergent de manière significative – y compris les différences d’ampleur, de cadrage ou d’interprétation – et de souligner les contributions uniques de chaque modèle », précise Gaurav Anand.
Des scores impressionnants à relativiser
Lors de tests internes avec le benchmark Draco, (deep research accuracy, completeness, and objectivity) qui évalue la qualité, la précision et la cohérence des analyses des modèles IA, Recherche utilisant Critique a surpassé les résultats basés sur de précédents modèles. « Nous constatons que la performance a augmenté de 3,33 points pour la portée et la profondeur de l’analyse, de 3,04 points pour la qualité de la présentation et de 2,58 points pour la précision factuelle », a indiqué Microsoft. « Toutes ces améliorations sont statistiquement significatives.» Cependant, les entreprises doivent les interpréter avec prudence. « Considérez-le comme un test dans des conditions idéales : il montre que les modèles IA peuvent se contrôler mutuellement et détecter des erreurs, mais les données réelles des entreprises sont beaucoup plus désordonnées, avec des informations contradictoires et des documents obsolètes », prévient Pareekh Jain, analyste principal chez Pareekh Consulting. « Il existe aussi un risque de biais : si les modèles se ressemblent, ils peuvent reproduire les mêmes erreurs sans que le système ne s’en rende compte. De plus, les tests évaluent surtout la logique, pas l’utilité réelle pour l’entreprise.»
« Les systèmes multi-modèles atteignent leur plein potentiel lorsqu’ils sont intégrés aux données internes de l’entreprise, comme les systèmes CRM et RH », note de son côté Neil Shah, vice-président recherche chez Counterpoint Research. « Cela garantit que les résultats générés par l’IA sont contextuellement nuancés, reflétant la position unique de l’entreprise sur le marché, les habitudes de ses clients et les besoins spécifiques des décideurs. »
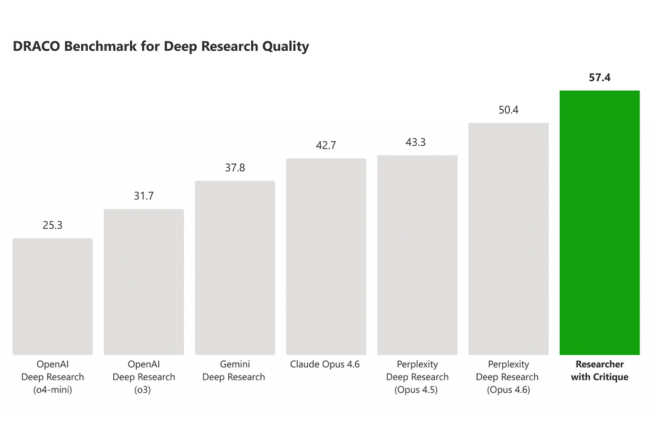
Copilot Recherche avec Critique a amélioré son score global de 13,8 % lors des tests DRACO, avec des gains sur l’analyse, la présentation et la précision. (Crédit: Microsoft)
Plus de modèles, plus de responsabilités
Le passage aux systèmes multi-modèles introduit de nouvelles couches de complexité opérationnelle pour les équipes IT. Les systèmes sont plus performants, mais plus difficiles à gérer. Plutôt que d’avoir un flux simple d’entrée-sortie, les entreprises doivent désormais suivre une chaîne d’interactions incluant le brouillon initial, la critique et le résultat final. « Cela crée une piste d’audit plus importante que les équipes sécurité et conformité doivent examiner pour comprendre comment les décisions ont été prises », ajoute Pareekh Jain. « Cela augmente également les coûts et la latence, car une seule question peut déclencher de multiples appels aux modèles. Autre défi, la responsabilité. Si quelque chose tourne mal, il est plus difficile de savoir quelle partie a échoué : le générateur, le relecteur ou le système qui les coordonne. »
Les analystes estiment que cela obligera les entreprises à repenser leurs cadres de gouvernance autour du déploiement de l’IA. « Les entreprises doivent prioriser la gouvernance du modèle jusqu’au processus de sélection des résultats, ainsi que l’affinement de la manière dont les multiples réponses sont combinées ou sélectionnées », explique Neil Shah. « Cette surveillance et calibration continue deviendront une composante fondamentale de la gestion de la qualité des processus. » Les entreprises devront également mettre en place des mécanismes structurés pour évaluer les résultats et leur impact réel, garantir la traçabilité tout au long du processus de décision et améliorer la gestion des systèmes multi-modèles au fil du temps, ajoute-t-il.