Le marché des bases de données NoSQL est aujourd’hui tellement vaste (MongoDB, DynamoDB, DataStax, CouchBase, Redis, MarkLogic ou encore Aerospike) qu’il est possible de choisir le produit le mieux adapté à ses besoins. Nous avons justement rencontré les cofondateurs d’Aerospike pour mieux comprendre les caractéristiques de leur base de données in-memory.
Brian Bulkowski, le CTO et cofondateur d’Aerospike, à Mountain View au siège de la start-up. (Crédit S.L.)
Longtemps chasse gardée de quelques éditeurs très bien implantés dans les entreprises, le marché des bases de données connaît une vive émulation grâce aux initiatives d’acteurs comme MariaDB, MongoDB ou PostgreSQL. SAP a aussi relancé la concurrence avec sa base de données in-memory HANA, disponible on-premise ou dans le cloud. Oracle s’est également mis à l’in-memory, et ce, bien après Aerospike, une start-up fondée en 2009 (anciennement CitrusLeaf) que nous avons rencontrée lors de notre dernier IT Press Tour à San Francisco.
Aerospike est une base de données NoSQL open source, in-memory, qui est fondamentalement un Key-Value store haute performance. Elle porte le nom d’un moteur de fusée dont le principal avantage est qu’il consomme moins de carburant à basse altitude qu’un moteur conventionnel. De type NoSQL, Aerospike Server a été conçue comme une base de données persistante ou un cache de données, capable d’assurer une faible latence dans les requêtes et un débit extrêmement élevé grâce à l’utilisation combinée de la RAM et de SSD. Afin de mieux appréhender l’augmentation des charges de travail dans les entreprises, elle supporte également la mise en clusters pour répondre aux besoins des applications distribuées. « Nous voulons apporter les technologies des géants de l’Internet à toutes les entreprises pour leurs applications de type real time big data », nous a expliqué Brian Bulkowski, le CTO et cofondateur de la société à Mountain View le mois dernier. « Nous devons encore éduquer sur l’utilisation de cette architecture, database in-memory et sans cache afin de casser les silos analytiques/transactionnels ». L’idée est d’apporter le plus de données possible au traitement analytique en cassant ces deux silos.
Données chaudes en mémoire, froides sur SSD
Les données stockées dans Aerospike peuvent être organisées en plusieurs conteneurs hiérarchiques. Certains systèmes NoSQL sont orientés document, ce qui signifie que les données sont encapsulées dans une sorte d’objet, typiquement JSON. Avec Aerospike, les conteneurs sont à peu près comme des documents, mais avec des fonctions et des comportements spécifiques à Aerospike. Chaque type de conteneur permet de définir des propriétés comportementales différentes sur les données qu’il contient. Par exemple, le niveau le plus haut des conteneurs, les espaces de noms, détermine si les données sont stockées sur SSD, en RAM, ou sur les deux ; si les données sont répliquées dans le cluster ou entre les clusters ; et quand ou comment les données expirées sont expulsées. Grâce aux espaces de noms, Aerospike permet aux développeurs de garder en mémoire les données les plus fréquemment consultées pour une réponse la plus rapide possible.
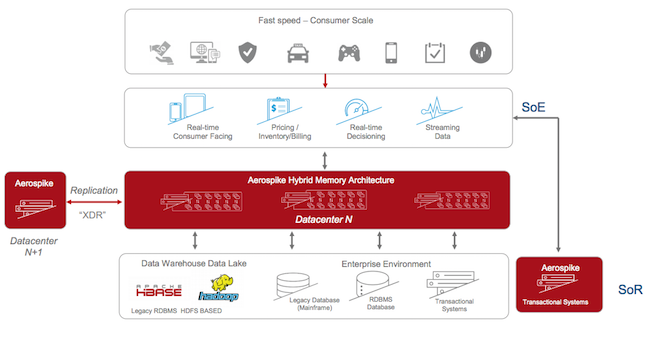
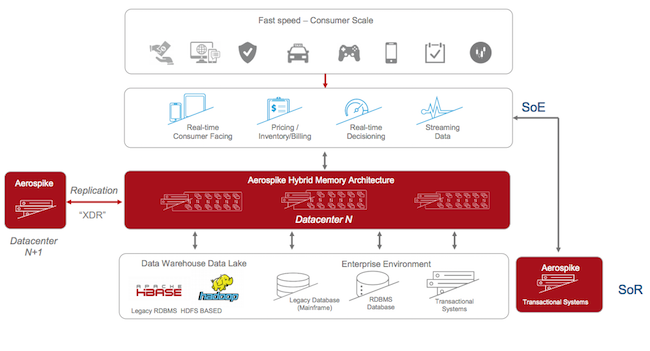
Aerospike travaille avec les principales plateformes du marché pour accélérer les requêtes.
Aerospike peut également stocker des données de type complexes – listes de valeurs, collections de paires de valeurs clés appelées cartes et données géospatiales au format GeoJSON. La base peut effectuer un traitement natif sur des données géospatiales – par exemple pour déterminer quels emplacements stockés dans la base de données sont les plus proches l’un de l’autre en effectuant simplement une requête – ce qui en fait une option attrayante pour les développeurs d’applications qui utilisent les emplacements géographiques.
Une liste des SSD recommandés
La base peut conserver ses données sur presque n’importe quel système de fichiers, mais elle a été écrite spécifiquement pour tirer parti des SSD en accédant directement aux blocs. Tous les SSD ne sont pas recommandés par l’éditeur qui tient une liste des dispositifs approuvés. Brian Bulkowski nous a même indiqué qu’ils avaient développé un outil baptisé ACT pour évaluer la performance des SSD avec les charges de travail d’Aerospike. Comme la plupart des systèmes NoSQL, Aerospike utilise une architecture sans partage (shared-nothing) pour la réplication et le clustering. La base n’a pas de nœuds maîtres et pas de répartition manuelle. Chaque nœud est identique. Les données sont réparties de manière aléatoire sur les nœuds et sont automatiquement rééquilibrées pour éviter la formation de goulets d’étranglement. Il est toutefois possible de définir des règles de rééquilibrage agressif des données et même de configurer plusieurs clusters, s’exécutant dans différents segments de réseau ou même dans différents datacenters, pour qu’ils se synchronisent les uns avec les autres. Le plus grand cluster Aerospike rassemble aujourd’hui vingt noeuds avec 400 serveurs.
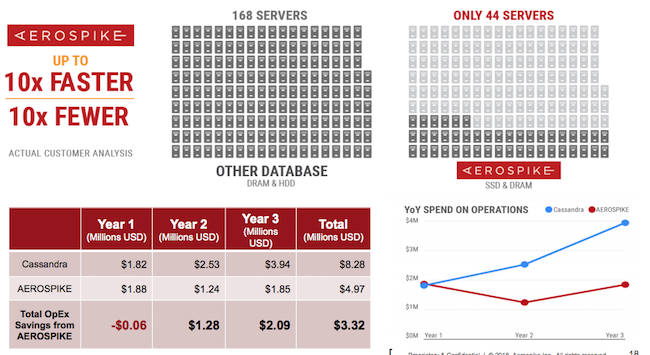
Le TCO est un des arguments mis en avant par Aerospike pour faire la différence.
Aerospike est disponible en édition communautaire gratuite et en édition entreprise payante. Le coût de l’édition entreprise dépend de la quantité de données stockées. La principale différence entre les deux éditions – autre que l’édition communautaire est sans support client 24-7 – est la réplication entre datacenters disponible dans l’édition entreprise, un processus qui s’exécute en parallèle avec le moteur Aerospike pour répliquer les données entre les clusters. La technologie hybride de la start-up est déjà utilisée chez Google, Facebook et AWS, nous a indiqué le CTO.