Selon Microsoft, le regroupement de produits existants comme Synapse et Power BI, au sein du service Fabric, offrira aux entreprises de combiner les charges de travail tout en réduisant leurs frais, la complexité et les coûts d’intégration IT.
A l’occasion de son évènement Build, Microsoft a annoncé le regroupement de ses produits existants d’entreposage de données, de veille stratégique et d’analyse de données dans une offre unique. Selon les analystes, l’offre, baptisée Fabric, pourrait aider les entreprises à combiner les charges de travail tout en réduisant leurs frais, la complexité et les coûts d’intégration IT. Selon Sanjeev Mohan, analyste principal chez SanjMo, le lancement de la plateforme d’analyse de données unifiée Fabric est peut-être une manière de répondre à la prolifération massive de produits dans la pile de données des entreprises. « Microsoft a compris que ses clients voulaient réduire leurs frais généraux et s’affranchir de la complexité de l’intégration. Ce n’est pas que les clients ne dépensent pas, mais ils cherchent une meilleure valeur pour leur investissement IT », a déclaré le consultant, ajoutant que si Fabric peut fournir de bons résultats, cette stratégie pourrait s’avérer payante pour le fournisseur de services de cloud public. « Outre une réduction de la complexité de l’IT, l’offre pourrait également contribuer à réduire les coûts », a ajouté l’analyste. « Une solution intégrée devrait coûter moins cher qu’un ensemble de solutions premium spécialisées. La solution Fabric pré-intégrée réduit aussi les coûts d’intégration et demande moins d’apprentissage et de compétences pour utiliser les différents outils ».
Microsoft affirme aussi qu’avec Fabric, il est plus simple d’acheter et de gérer les ressources. « Les clients peuvent acheter un seul pool de calcul qui alimente toutes les charges de travail Fabric. Les capacités de calcul universelles réduisent considérablement les coûts, car toute capacité de calcul inutilisée dans une charge de travail peut être utilisée par n’importe quelle autre charge de travail », a expliqué l’entreprise dans un communiqué. Selon Boris Evelson, analyste principal chez Forrester, les données brutes, qu’elles soient transactionnelles, opérationnelles ou autres, doivent passer par des étapes comme la collecte, l’ingestion, l’extraction, le déplacement, l’intégration, le nettoyage, la modélisation et le catalogage avant d’être transformées en informations utiles. « Généralement, certaines des technologies qui prennent en charge chacune de ces étapes proviennent de différents fournisseurs et les professionnels des données ou de l’analyse doivent consacrer du temps à l’intégration », a déclaré M. Evelson, ajoutant que si Fabric ne supprime pas complètement l’étape de l’intégration des composants, elle réduit le temps et les efforts d’intégration, et permet aux utilisateurs des données et de l’analytique de se concentrer davantage sur la résolution de problèmes et sur la recherche d’opportunités commerciales.
Sept services et outils principaux
Selon le fournisseur, l’architecture unifiée de Fabric offre une expérience SaaS (Software-as-a-Service) qui aide les développeurs à extraire des informations à partir de données brutes et à les présenter aux utilisateurs métiers. « La nouvelle suite analytique comprend sept modules et outils principaux, notamment des connecteurs de données, des outils d’ingénierie des données, des flux de travail pour la science des données et des outils analytiques, entre autres choses », a ajouté l’entreprise. « Le module Data Factory, actuellement en preview public, fournit plus de 150 connecteurs à des sources de données dans le cloud et sur site, avec la possibilité d’utiliser le glisser-déposer pour la transformation des données et d’orchestrer des pipelines de données », a encore déclaré l’entreprise. Microsoft a également intégré le module Synapse Data Engineering qui facilite la création de modèles dans Apache Spark. « Fabric comprend également Synapse Data Science, un workflow de bout en bout pour les scientifiques des données pour construire des modèles d’IA sophistiqués, et Synapse Data Warehousing, qui combine des outils de lakehouse et d’entreposage de données avec la possibilité d’exécuter SQL sur des formats de données ouverts », a par ailleurs déclaré l’entreprise. Les deux sont disponibles en aperçu public. « De même, le module Synapse Real-Time Analytics, également en aperçu public offre aux développeurs de travailler avec des données en continu et d’analyser de grands volumes de données semi-structurées », a indiqué Microsoft. Le fournisseur a aussi intégré un module Power BI dans Fabric pour aider les analystes et les utilisateurs professionnels à générer des informations à partir des données avec l’appui d’outils basés sur l’IA.
Synapse Data Engeneering fait partie du package de Fabric. (Crédit Photo: Microsoft)
L’expérience Power BI est aussi profondément intégrée dans Microsoft 365. Pour Hyoun Park, analyste principal chez Amalgam Insights, « l’ajout de Power BI à Fabric comble un certain nombre de lacunes qui rendaient Power BI moins adapté aux entreprises par rapport à des plateformes analytiques comme Qlik, Tibco ou SAS ». Fabric sera livré avec un module Data Activator destiné à la détection et à la surveillance en temps réel des données. « Le module pourra déclencher des notifications et des actions quand il trouvera des modèles spécifiques dans les données », a expliqué l’entreprise, ajoutant que Data Activator était actuellement disponible en aperçu privé. Toujours selon Microsoft, il est possible de tester les sept modules sur le portail de l’entreprise.
Azure OpenAI ajouté à Fabric, et bientôt Copilot
Microsoft a annoncé l’ajout du service Azure OpenAI à Fabric et l’intégration prochaine de Copilot, alimenté par GPT, à la plateforme analytique. « Avec l’intégration de Copilot à Microsoft Fabric, les utilisateurs pourront utiliser le langage conversationnel pour créer des flux de données et des pipelines de données, générer du code et des fonctions entières, construire des modèles d’apprentissage machine ou visualiser les résultats », a déclaré l’entreprise. « L’ajout du service Azure OpenAI et de Copilot accélérera considérablement le travail effectué par les professionnels des données dans Azure en supprimant bon nombre de barrières entre les solutions », a déclaré Bradley Shimmin, analyste en chef chez Omdia.
Copilot va bientôt faire ses premiers pas dans PowerBI. (Crédit Photo: Microsoft)
« Cela devrait également accélérer l’adoption des modèles fondamentaux de Microsoft et très probablement de tout le portefeuille d’outils d’apprentissage machine de l’entreprise », a ajouté M. Shimmin. Sanjeev Mohan, l’analyste principal de SanjMo, pense aussi que cette décision témoigne de l’effort continu de Microsoft pour intégrer les API des grands modèles de langage d’OpenAI à l’ensemble de son portefeuille. « Les entreprises peuvent aussi combiner les grands modèles de langage du service Azure OpenAI avec leurs propres données pour créer leurs propres expériences de langage conversationnel », a déclaré Microsoft, ajoutant que Copilot n’a pas été formé sur les données d’un tenant de l’entreprise.
Prise en charge de OneLake et adoption du format Delta de Databricks
Selon Microsoft, à l’instar des données des applications 365, stockées dans OneDrive, toutes les données et charges de travail de Fabric sont stockées dans un lac de données SaaS et multi-cloud appelé OneLake. « Les données sont organisées dans un hub de données et automatiquement indexées pour la découverte, le partage, la gouvernance et la conformité. Il s’agit d’un système de stockage unique et unifié pour tous les développeurs, où la découverte et le partage des données sont faciles, avec des paramètres de politique et de sécurité appliqués de manière centralisée », a déclaré l’entreprise dans un communiqué. « Cela évite les silos de données liés au fait que les différents développeurs provisionnent et configurent leurs propres comptes de stockage isolés », a encore expliqué Microsoft, ajoutant que « OneLake propose aux entreprises de virtualiser le stockage du datalake dans ADLS Gen2, AWS S3, et Google Storage ».
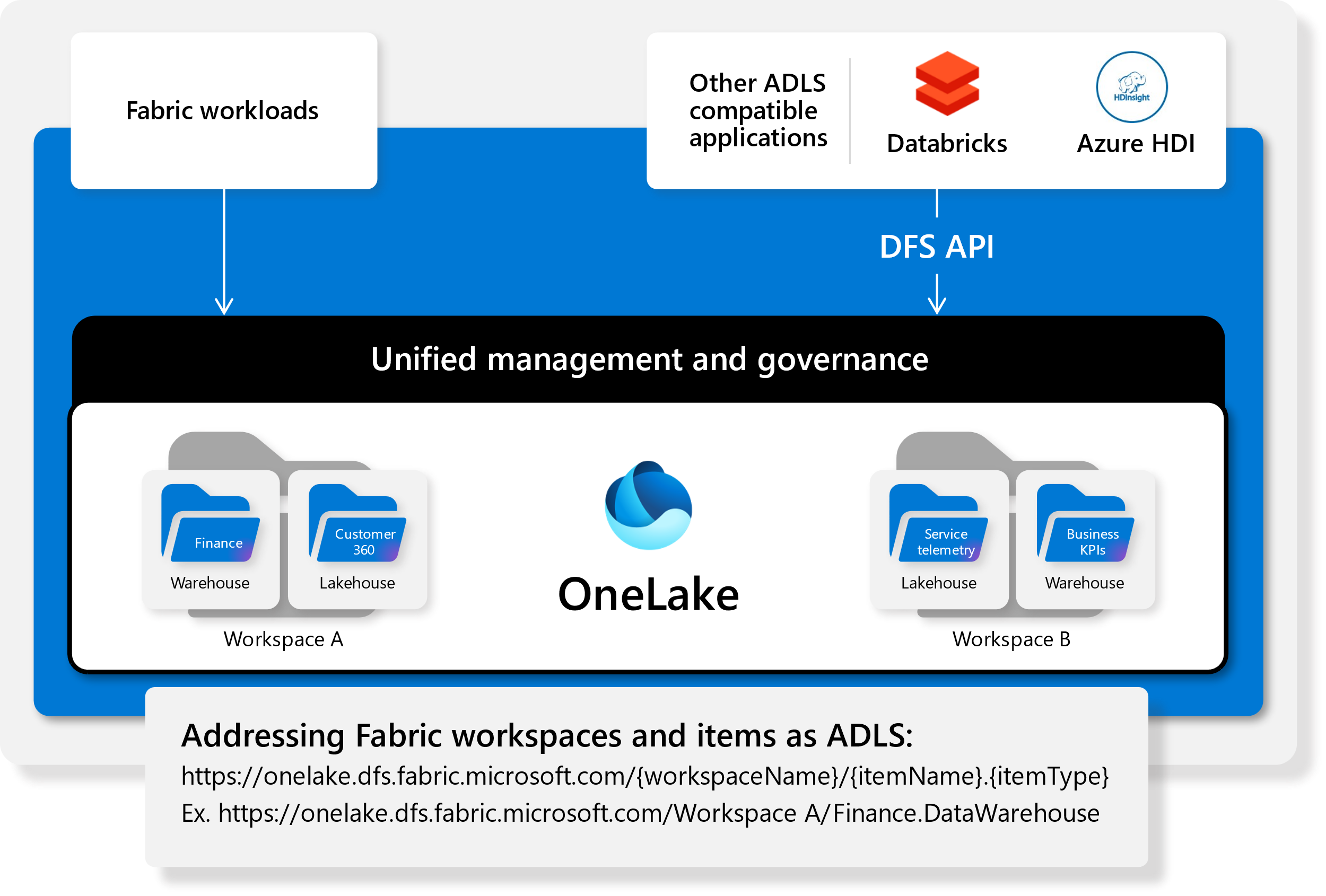
OneLake supporte les mêmes API et SDK ADLS Gen2 pour être compatible avec les applications ADLS Gen2 existantes, y compris Azure Databricks. Les données dans OneLake peuvent être traitées comme s’il s’agissait d’un seul grand compte de stockage ADLS pour l’ensemble de l’organisation. (Crédit : Microsoft)
Selon M. Evelson de Forrester, avec OneLake, les entreprises pourront créer plus facilement leur propre mini-lac de données en quelques minutes plutôt qu’en quelques jours ou semaines. « Certes, il faudra encore du temps pour que ce lac de données soit prêt pour les applications critiques, mais le prototypage, les PoC et le développement agile seront plus commodes », a déclaré l’analyste. En outre, Fabric traite Delta au-dessus des fichiers Parquet comme un format de données natif qui est la valeur par défaut pour toutes les charges de travail. « Cet engagement profond en faveur d’un format de données ouvert commun signifie que les clients n’ont besoin de charger les données qu’une seule fois dans le lac de données et que toutes les charges de travail peuvent fonctionner sur les mêmes données, sans avoir à les ingérer séparément », a déclaré l’entreprise. « Autrement dit, OneLake prend en charge les données structurées de n’importe quel format et les données non structurées », a-t-elle ajouté.
Boris Evelson estime que l’adoption du format open source pourrait représenter un énorme gain de temps, d’efforts et d’espace de stockage. « Même si OneLake n’est pas lui-même open source, la structure des données est basée sur un format de données open source appelé Parquet, optimisé pour l’analyse. Cela signifie qu’un lac de données, un entrepôt de données et une plateforme de BI (dans ce cas, Power BI) utiliseront exactement le même format et, surtout, la même instance/version des données », a déclaré Boris Evelson. De plus, Microsoft a déclaré qu’elle prévoyait d’introduire un modèle de sécurité universel pour le Fabric géré dans OneLake afin d’aider les entreprises à gérer la sécurité des données à travers différents moteurs de données, modules ou outils. « Ce modèle garantira que tous les moteurs ou modules de données appliquent le modèle de sécurité quand ils traitent des requêtes ou d’autres tâches », a indiqué l’entreprise.
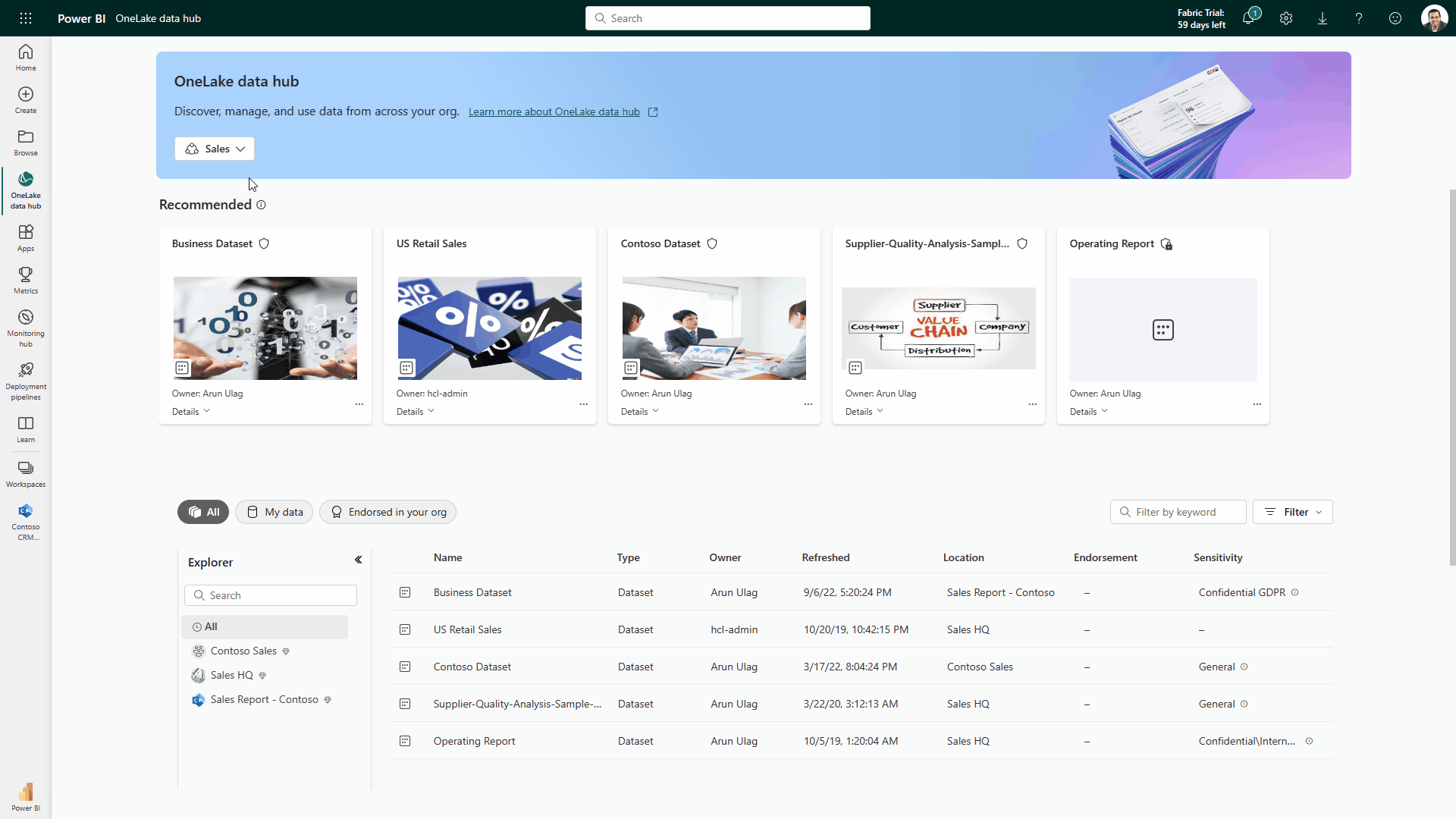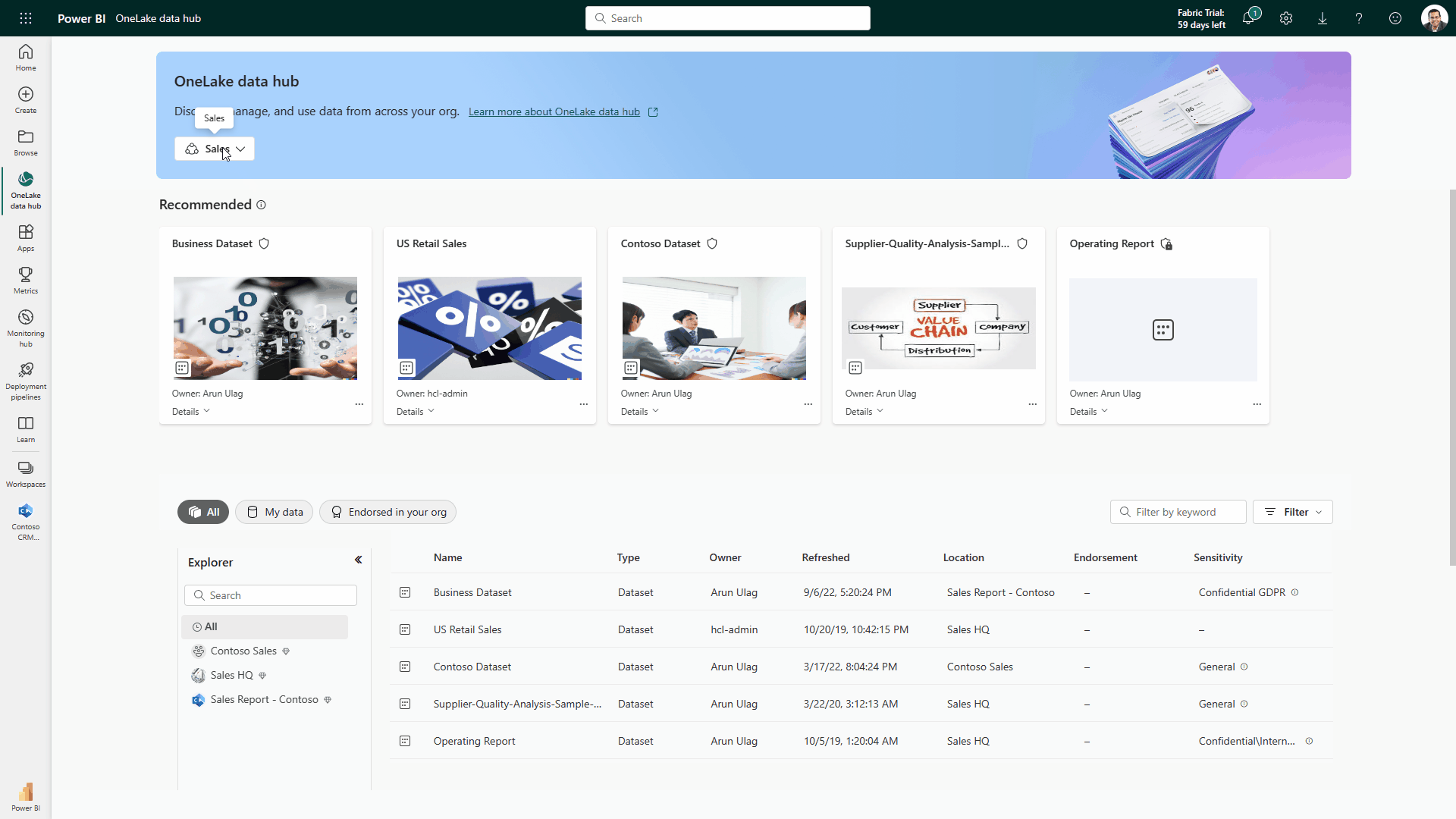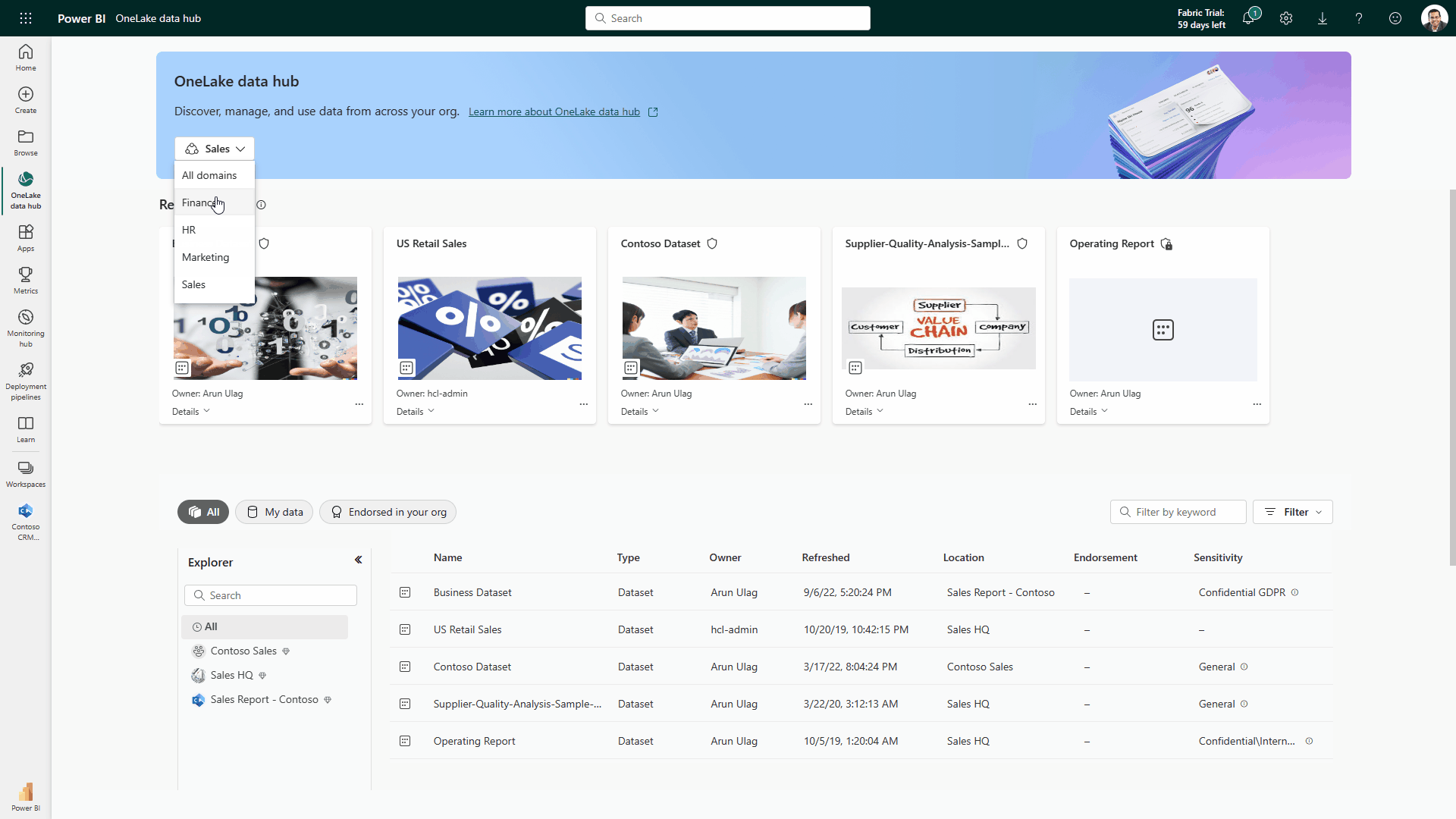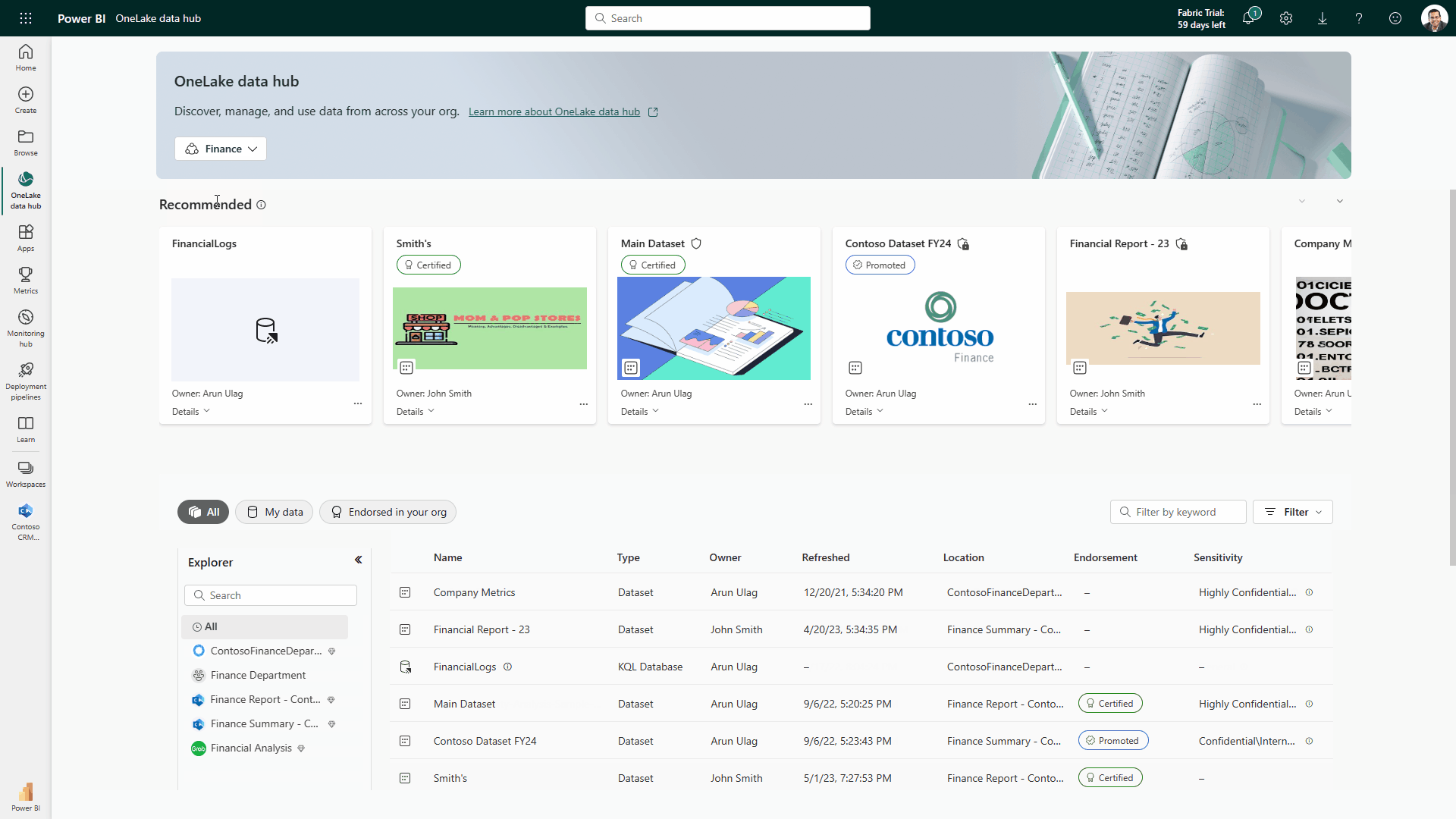
Avec les domaines OneLake intégrés, OneLake est le premier lac de données qui offre un support natif pour le maillage de données en tant que service. (Crédit : Microsoft)
Une capitalisation qui ne va pas de soi
Selon les analystes, le lancement de Microsoft Fabric pourrait avoir un impact sur son adoption et sa popularité. « Si chaque entreprise utilisatrice d’Office 365 reçoit une copie de Fabric, tout comme elle reçoit actuellement une copie de Power BI avec la licence E5 Office 365, elle aura le même effet viral que Power BI », a déclaré Boris Evelson. Cependant, Doug Henschen, analyste principal chez Constellation Research pense qu’il ne faut pas s’empresser de miser sur un succès immédiat de Fabric. « Nous devons garder à l’esprit que tout ce qui a été annoncé est encore en aperçu et que jusqu’à présent, la réussite de Microsoft dans des domaines comme l’entreposage de données reste mitigée.
« Plus récemment, Azure Synapse n’a pas été adoptée massivement ni acclamé par les clients comme plateforme de stockage de données », a aussi déclaré M. Henschen, ajoutant que les entreprises ne changent généralement pas rapidement de plateforme de données. Selon les analystes, Microsoft Fabric peut être comparé à Google DataPlex, SAP DataSphere et IBM Data Fabric.