En combinant un cache distribué avec une accélération matérielle sur puce FPGA, AWS accélère avec Aqua la performance des requêtes sur son datawarehouse Redshift. Celles-ci peuvent être jusqu’à 10 fois plus rapides.
Depuis la sortie de Redshift d’AWS en 2012, le paysage des datawarehouses cloud a été bousculé par l’arrivée de Snowflake qui emporte une forte adhésion sur un marché où l’on trouve aussi Azure SLQ DW, Big Query de Google, Autonomous DW d’Oracle ou encore l’offre de Databricks. Pour faire monter sa solution en puissance, la filiale cloud d’Amazon prépare depuis un an une fonctionnalité de cache distribué accélérée par matériel conçue pour doper la performance des requêtes sur Redshift. Côté matériel, cette option s’appuie sur des instances Nitro et sur des puces d’accélération FPGA. Fournie en préversion en décembre, Aqua – Advanced query accelerator – est maintenant disponible dans sa version définitive sur plusieurs régions cloud AWS dont l’Europe, en Irlande et à Francfort, les Etats-Unis et Tokyo.
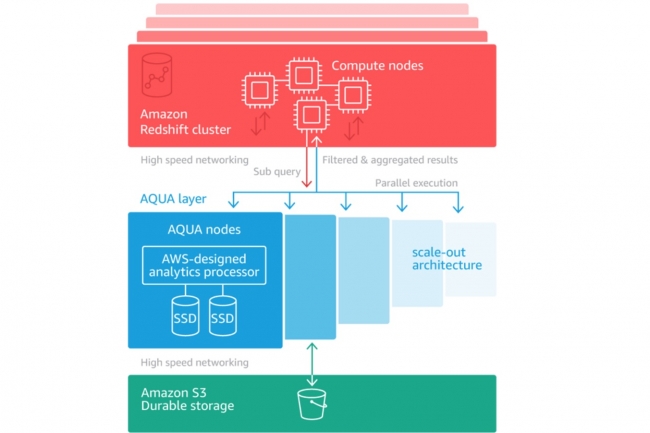
Aqua amène les ressources de calcul au niveau de la couche stockage pour éliminer les mouvements de données transitant sur le réseau entre l’emplacement où elles sont stockées et les clusters de compute. L’accélération ainsi apportée sur les performances des requêtes peut aller jusqu’à un facteur 10, assure AWS. Cette fonctionnalité de cache est accessible sur les instances Redshift RA3 sans coût additionnel et sans entraîner de modification sur le code des applications pour les clients.
Une connexion haut débit à S3
Sur son service Redshift, AWS affirmait déjà fournir un rapport prix/performance supérieur à ses concurrents par la conception du matériel utilisé et l’utilisation de l’apprentissage machine. Dans un billet publié cette semaine, Jeff Barr, chef évangéliste du fournisseur cloud, rappelle ainsi que Redshift dispose depuis fin 2019 de noeuds RA3 basés sur des SSD, complétés en 2020 par d’autres noeuds bénéficiant d’une bande passante réseau optimisée et d’un autre modèle de gestion des données avec un placement automatique des données au niveau approprié. Avec ces noeuds RA3, il est possible de monter jusqu’à 32 Po de données dans un seul datawarehouse. Mais les avancées sur les performances du stockage par rapport aux CPU ont conduit à chercher une solution permettant de s’affranchir des facteurs limitants des CPU et du réseau.
« Aujourd’hui, nous rendons les noeuds ra3.4xl et ra3.16xl encore plus puissants avec l’addition d’Aqua », indique Jeff Barr. En tirant parti des caches, de Nitro (matériel dédié combiné à un hyperviseur léger) et de puces d’accélération FPGA, Aqua pousse plus près des données les besoins en calcul nécessaire pour réduire et agréger les requêtes, apportant l’amélioration de performances affichée. A cela s’ajoute l’utilisation d’une connexion haut débit au service de stockage S3. « Les bénéfices sont apportés de plusieurs façons », explique Jeff Barr. « Chaque noeud effectue les opérations de réduction et d’agrégation en parallèle avec les autres. En plus d’obtenir l’accélération apportée par le parallélisme, la quantité de données qui doit être envoyée et traitée par les noeuds de compute est généralement beaucoup plus petite, souvent 5% par rapport à l’original ». Les clients Redshift qui utilisent déjà des noeuds ra3.4xl ou ra3.16xl pour leur entrepôt de données cloud peuvent commencer à tirer parti d’Aqua en quelques minutes, assure le chef évangéliste. Il suffit d’activer Aqua pour les cluster et les redémarrer.