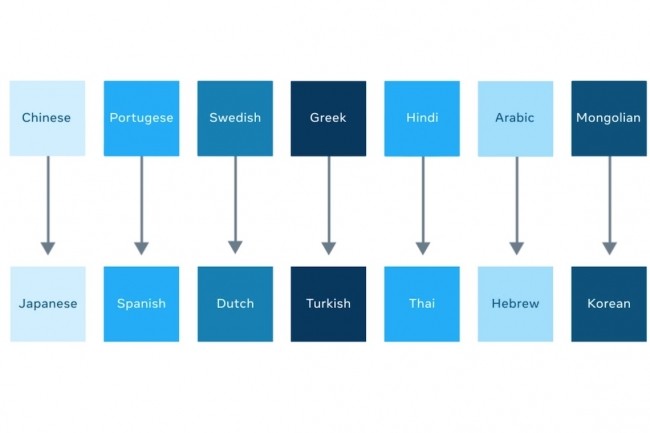
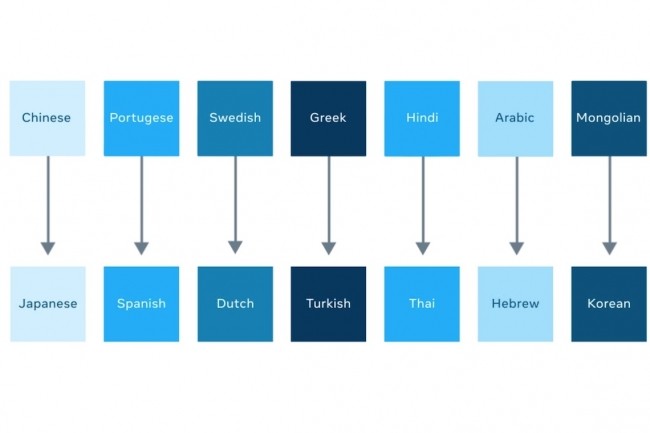
La particularité du modèle M2M-100, versé dans l’open source par le laboratoire d’IA de Facebook, est de traduire automatiquement 100 langues entre elles sans passer par le pivot de l’anglais.
L’une des plus grandes difficultés pour construire un modèle de traduction multilingue many-to-many, explique Facebook, est de réunir de grands volumes de paires de phrases de qualité entre langues qui ne transitent pas par l’anglais. (Crédit : Facebook)
Coutumier des apports à l’open source, le laboratoire de recherche en intelligence artificielle de Facebook livre cette fois sur GitHub un modèle de traduction automatique multilingue (MMT) dénommé M2M-100. Celui-ci peut traduire entre n’importe quelle paire de langues parmi 100 langues sans s’appuyer au passage sur l’anglais, qui sert généralement de langue intermédiaire à la plupart des modèles. Pour une traduction du chinois vers le français, « notre modèle s’entraîne directement sur les données en chinois vers le français pour mieux préserver le sens », explique Angela Fan, assistante de recherche à Facebook IA, dans un billet. Elle ajoute qu’après évaluation par l’algorithme BLEU (bilingual evaluation understudy portant sur la qualité de la traduction automatique), ce modèle surpasse de 10 points les systèmes centrées sur l’anglais.
M2M-100 est entraîné sur un total de 2 200 directions linguistiques, soit 10 fois plus que les meilleurs modèles multilingues centrés sur l’anglais, souligne Facebook AI en estimant qu’il peut améliorer la qualité de traduction pour « des milliards de personnes », en particulier sur les langues pour lesquelles il existe peu de ressources. Ce qui peut aussi contribuer à améliorer l’accès aux informations de source officielle, par exemple sur les communications liées au Covid-19. Chaque jour, 20 milliards de traductions sont opérées sur le fil de News Facebook, rappelle le réseau social.
Un jeu de 7,5 milliards de paires de phrases sur 100 langues
Facebook AI accompagne son modèle d’explications sur ses travaux afin d’aider les autres chercheurs engagés sur cette voie. Le volume de données requis pour l’entraînement du modèle augmente considérablement avec le nombre de langues supportées : s’il faut 10 millions de paires de phrases pour chaque direction, il faut en traiter 1 milliard de paires pour 10 langues et 100 milliards de paires pour 100 langues. Pour relever ce défi, les chercheurs ont créé un jeu de données MMT many-to-many de 7,5 milliards de paires de phrases sur 100 langues pour entraîner leur modèle. Ils l’ont fait en combinant des ressources de data mining complémentaires élaborées depuis des années dont ccAligned, ccMatrix et LASER, et en créant un LASER 2.0. Le modèle MMT a été mis à l’échelle jusqu’à exploiter 15 milliards de paramètres. M2M-100 s’appuie sur le modèle de compréhension multilingue XLM-R de Facebook, entraîné sur 2,5 To de pages web.
Parmi ses nombreux travaux sur les langues, Facebook AI a également publié cet été sur arxiv.org ses recherches pour améliorer la reconnaissance automatique de la parole sur plus de 50 langues.