
Pour monter en puissance et coller ses concurrents américains, la start-up française Mistral AI a dévoilé Mixtral 8x22B, un grand modèle de langage open source sous licence Apache 2.0. Basé sur du mélange d’experts, ce modèle montre des capacités intéressantes en termes de raisonnement et de codage.
Encore minoritaires sur le marché des LLM, les grands modèles de langage open source sont souvent appréciés de leurs utilisateurs davantage pour leurs capacités de personnalisation et de contrôle (sécurité et confidentialité des données) que pour leurs performances. Mais pourquoi pas réussir à marier le meilleur des deux mondes ? Un défi que Mistral AI tente de relever avec son modèle Mixtral 8x22B, dernier rejeton de la start-up française en matière de LLM open source après Mistral 7B et Mixtral 8x7B. « Il établit une nouvelle norme de performance et d’efficacité au sein de la communauté de l’IA », avance Mistral AI. « Il s’agit d’un modèle de mélange d’experts peu dense (SMoE) qui n’utilise que 39 milliards de paramètres actifs sur 141 milliards, ce qui offre une rentabilité inégalée pour sa taille ».
Mistral AI a publié des éléments comparatifs de performance avec ses deux précédents modèles open source et celui de Meta (Llama2 70B) mais pas avec d’autres LLM propriétaires (Google Gemini AI, OpenAI GPT, Anthropic Claude…). Une situation à laquelle la communauté à remédier en publiant sur Hugging Face des données complémentaires. « Les résultats semblent se rapprocher des modèles fermés développés par Google et OpenAI », résume Saptorshee Nag, rédacteur de contenu technique sur la plateforme de tutorat en ligne FavTutor. « Les premières réactions de la communauté de l’IA ont été largement positives. Nombreux sont ceux qui sont enthousiasmés par les nouvelles utilisations et les recherches révolutionnaires que Mixtral 8x22B rendra possibles ».
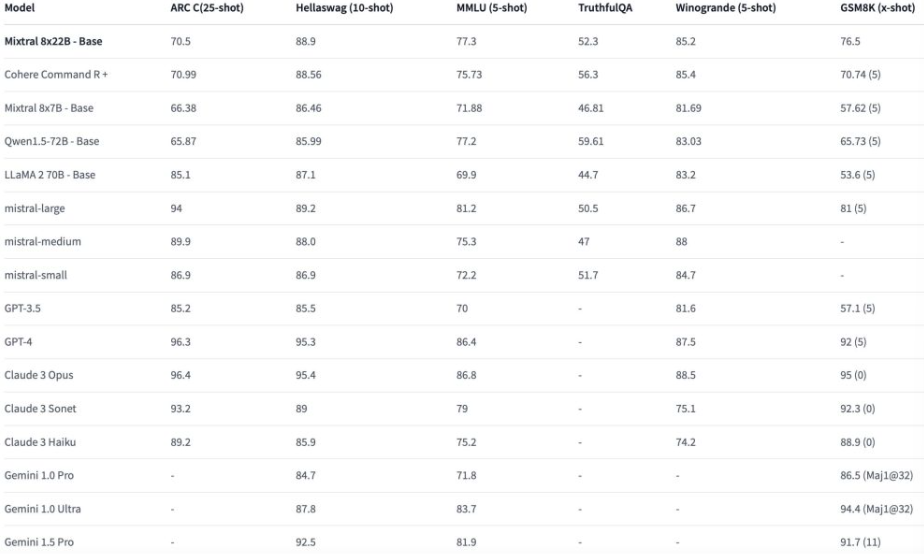
Evaluation comparée des capacités du LLM Mixtral 8x22B de Mistral AI avec d’autres grands modèles de langage commerciaux ou open source. (crédit : Hugging Face)
Un LLM plutôt bon en calcul et en raisonnement
La jeune pousse avance que son LLM dispose de capacités d’appel de fonction natives (pratiques pour développer des applications à grande échelle) et d’une fenêtre contextuelle de 64K tokens pour rappeler des informations précises à partir de documents volumineux. « Mixtral 8x22B est le modèle open source le plus puissant avec un nombre significativement inférieur de paramètres que ses concurrents et surpasse Llama 2 70B sur la plupart des benchmarks avec une inférence 6 fois plus rapide », assure l’éditeur.
Mistral AI explique que Mixtral 8x22B est taillé pour les tâches intermédiaires requérant un raisonnement modéré comme l’extraction de données, le résumé d’un document, la rédaction d’une description de poste ou d’une description de produit, et qu’il parle couramment l’anglais, le français, l’italien, l’allemand et l’espagnol. Mais aussi qu’il possède de bonnes compétences en mathématiques et en codage. « Mixtral 8x22B obtient un bon score de 76,5 [sur le critère GSM8K], mais il se situe une fois de plus derrière les familles GPT, Claude et Gemini. Vous pouvez utiliser Mixtral pour des problèmes mathématiques normaux et moyens, mais préférez Claude et Gemini pour des problèmes complexes nécessitant des capacités de traitement plus importantes », tempère cependant Saptorshee Nag.
Tout comme les autres LLM open source de Mistral AI, Mixtral 8x2B est payant : 1,9€/1 million tokens en input et 5,6€/1M tokens en output. Des tarifs bien supérieurs à ceux d’open-mixtral-8x7b à 0,65€/1M tokens aussi bien en input qu’en output.