
D’après la première étude importante sur l’hallucination de paquets, les LLM pourraient être exploités pour lancer des vagues d’attaques par « confusion de paquets ».
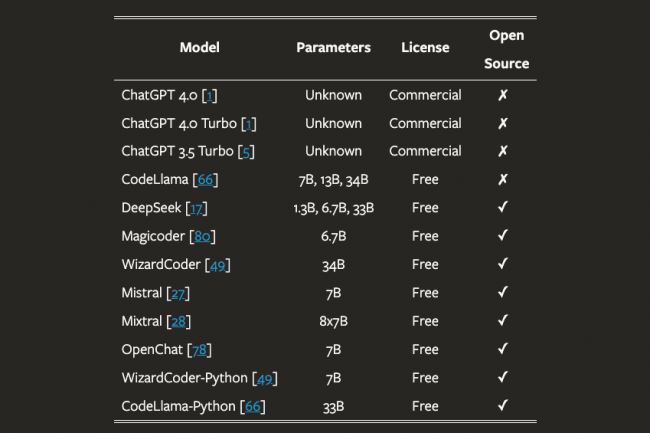
Dans l’une des études les plus étendues et les plus approfondies jamais réalisées sur le sujet, des chercheurs universitaire (Université de San Antonio au Texas, Université de Virginie et Université de l’Oklahoma) ont découvert que les grands modèles de langage (LLM) présentaient un sérieux problème d’hallucination de paquets que des attaquants pourraient exploiter pour introduire des paquets codés malveillants dans la chaîne d’approvisionnement. Le problème est tellement grave…
Il vous reste 94% de l’article à lire
Vous devez posséder un compte pour poursuivre la lecture
Vous avez déjà un compte?