
Nvidia se prépare à livrer la plate-forme serveur HGX-2 qui sera capable d’exploiter la puissance de 16 GPU Tesla V100 Tensor Core, contre 8 pour le modèle précédent HGX-1. Plusieurs fabricants annoncent qu’ils livreront des systèmes HGX2 d’ici la fin de l’année.
La plate-forme HGX-2 de Nvidia est un socle de base autour duquel les fournisseurs de serveurs peuvent construire des systèmes adaptés aux différents besoins d’intelligence artificielle et de calcul HPC. (Crédit : Nvidia)
Tout juste annoncée, la plateforme Nvidia HGX-2 entend répondre aux exigences des charges de travail d’intelligence artificielle et de calcul haute performance (HPC) les plus intensives. Les fabricants de serveurs pour datacenter Lenovo, Supermicro, Wiwynn et QCT ont déclaré qu’ils expédieraient des systèmes HGX-2 d’ici la fin de l’année. Il est probable que les systèmes HGX-2 intéresseront aussi les fournisseurs de datacenters hyperscale. Ce n’est donc pas surprenant de voir que Foxconn, Inventec, Quanta et Wistron préparent des serveurs basés sur cette plate-forme pour datacenters dans le cloud.
Le HGX-2 est construit sur deux cartes GPU reliant les GPU Tesla via un fabric d’interconnexion NVSwitch. Chaque carte HGX-2 gère 8 processeurs, pour un total de 16 GPU. C’est deux fois plus que le HGX-1, annoncé il y a un an, qui ne supportait que 8 GPU. Selon Nvidia, le HGX-2 est « un socle de base » que les fabricants de serveurs pourront moduler pour construire des systèmes adaptés à des tâches différentes. Nvidia utilisera la même base HGX2 pour sa future plateforme DGX-2. La seule différence, c’est que l’entreprise met la plate-forme et son architecture de référence à la disposition des fabricants de serveurs afin qu’ils puissent livrer des systèmes d’ici la fin de l’année. L’annonce sera faite aujourd’hui par Jensen Huang, le CEO de Nvidia, lors de la GPU Technology Conference organisée à Taiwan les 30 et 31 mai.
2 pétaflops dans un seul DGX-2
Il y a deux mois, lors de la précédente édition de la GPU Technology Conference organisée à San José, en Californie, Nvidia a déclaré que le DGX-2, qui devrait être le premier système disponible basé sur le socle HGX-2, sera capable de fournir deux pétaflops de puissance de calcul, une performance qui n’était jusqu’ici accessible qu’à des centaines de serveurs en cluster. Le prix des systèmes DGX-2 démarre à 399 000 dollars HT. Nvidia a déclaré que les systèmes HGX-2 de test évalués par le benchmark de training ResNet-50 ont atteint des vitesses records de 15 500 images par seconde, et peuvent remplacer jusqu’à 300 serveurs basés sur des CPU dont le coût dépasserait plusieurs millions de dollars.

En quelques années, Jensen Huang, le CEO de Nvidia, a réussi à bâtir un business de près de 10 milliards de dollars dans le calcul intensif dédié à l’IA.
Les GPU répondent bien aux besoins d’apprentissage des ensembles de données pour les applications d’apprentissage machine, en particulier pour la création de modèles de réseaux neuronaux. L’architecture massivement parallèle des GPU les rend particulièrement adaptés aux tâches d’apprentissage de l’intelligence artificielle. Dans ses arguments de vente, Nvidia insiste sur le fait que le HGX-2 peut être configuré aussi bien pour l’apprentissage de l’IA que pour les tâches d’inférence qui permettent l’usage des réseaux neuronaux dans des situations réelles. Le HGX-2 cible également les applications HPC en informatique scientifique, le rendu d’images et de vidéos, et les simulations. « Nous pensons que l’informatique de demain a besoin d’une plate-forme unifiée », a déclaré Paresh Kharya, Group Product Marketing Manager, Intelligence artificielle et informatique accélérée, chez Nvidia. « Ce qui est vraiment unique à propos du HGX-2, c’est sa capacité de calcul numérique en multi-précision ». M. Kharya a expliqué que la plate-forme permettait des calculs haute précision utilisant jusqu’à 64 FP64 – soit, 64 bits en double précision mathématique – pour le calcul scientifique et les simulations, tout en offrant du FP16 (arithmétique à virgule flottante de 16 bits) et de l’Int8 (un type d’instruction d’inférence) pour les charges de travail d’intelligence artificielle.
Interconnexion simultanée
« Chaque socle de base HGX-2 héberge six commutateurs NVS qui sont des commutateurs non bloquants avec 18 ports, de sorte que chaque port peut communiquer avec n’importe quel autre port à pleine vitesse NVLink », a encore déclaré Nvidia. NVlink est la technologie d’interconnexion de Nvidia, déjà licenciée par IBM. Les deux socles GPU de chaque plate-forme HGX-2 communiquent via 48 ports NVLink. « La topologie permet aux 16 GPU (huit sur chaque carte) de communiquer avec n’importe quel autre GPU simultanément à des vitesses NVLink de 300 Go par seconde », a aussi précisé Nvidia. « Nous sommes en train de dépasser beaucoup de frontières classiques avec ce système », a déclaré Paresh Kharya. « Nous repoussons les limites de ce qu’un seul système peut faire avec 10 kilowatts de puissance ».
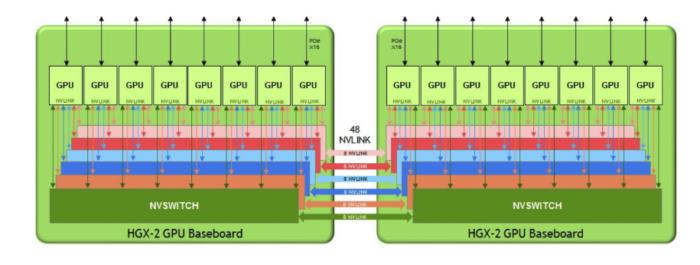
La topologie des systèmes basés sur le GPU HGX-2 de Nvidia permet aux 16 GPU V100 Tensor Core de Nvidia d’être connectés simultanément. (Crédit : Nvidia)
Nvidia proposera huit types de plates-formes serveur accélérées par GPU, intégrant chacune deux processeurs Xeon. Chaque modèle contient un nombre de noyaux GPU différent et chacun est configuré pour des besoins différents en IA et en calcul haute performance. Dans le haut de la gamme, on trouve le HGX-T2 de Nvidia : basée sur le HGX-2, cette plateforme adaptée au training des très gros réseaux neuronaux d’apprentissage machine multiniveaux comporte 16 GPU Tesla V100. Dans le bas de gamme, Nvidia propose le SCX-E1 avec deux GPU Tesla V100. Cette version destinée à l’informatique HPC d’entrée de gamme intègre la technologie d’interconnexion PCIE et consomme 1 200 watts. Dans la nomenclature de Nvidia, les systèmes HGX-T sont destinés à l’apprentissage de l’IA, les systèmes HGX-I sont destinés à l’inférence pour l’IA et les systèmes SCX sont destinés au HPC et au calcul informatique scientifique.
Même si Nvidia a une emprise solide sur le marché des GPU pour les charges de travail de l’IA, le fondeur n’échappera pas à la concurrence croissante de plusieurs rivaux. Intel, qui a racheté Nervana Systems en 2016, met une touche finale à son processeur Intel Nervana Neural Network Processor (NNP). Et des fabricants de FPGA comme Xylinx proposent des puces programmables « Field Programmable Gate Arrays » de plus en plus puissantes déjà utilisées pour l’inférence en IA. Si les puces FPGA n’offrent pas une performance brute suffisante pour rivaliser avec les GPU pour l’apprentissage de l’IA, elles peuvent être programmées pour traiter chaque couche d’un réseau neuronal déjà établi, avec le minimum de précision nécessaire, une flexibilité idéale pour les tâches d’inférence.