La start-up californienne Qubole a intégré sa solution de traitement des big data avec le datawarehouse de Snowflake. Les utilisateurs de Qubole peuvent ainsi accélérer le déploiement de modèles d’apprentissage machine réalisés avec Apache Spark en s’appuyant sur les données stockées dans Snowflake.
Le service cloud de traitement des big data de Qubole peut maintenant travailler avec les données stockées dans le datawarehouse cloud de Snowflake (ci-dessus, l’interface d’exploration de Qubole affiche les tables et objets accessibles dans Snowflake).
Qubole et Snowflake, deux start-ups de la Silicon Valley proposant des solutions cloud natives, l’une pour les traitements les big data, l’autre pour bâtir un datawarehouse, viennent d’intégrer leurs services. Les équipes chargées des projets big data vont ainsi pouvoir construire et entraîner des modèles d’apprentissage machine avec Apache Spark dans Qubole en utilisant des données stockées dans le datawarehouse de Snowflake. En automatisant les connexions entre leurs deux services cloud, les fournisseurs ont supprimé l’étape complexe de configuration manuelle de Spark. L’objectif est également de pouvoir réduire les temps de déploiement des modèles de machine learning et d’intelligence artificielle.
L’intégration entre les services cloud permet aussi, depuis Qubole, de travailler sur les informations gérées dans Snowflake pour toutes les opérations de data wrangling consistant à préparer et à enrichir des jeux de données. Enfin, les connexions entre Qubole et Snowflake permettent un accès unique et sécurisé aux deux services, ainsi que l’utilisation des données de Snowflake par les langages de programmation Scala et Python via l’API Dataframe pour Apache Spark de Qubole.
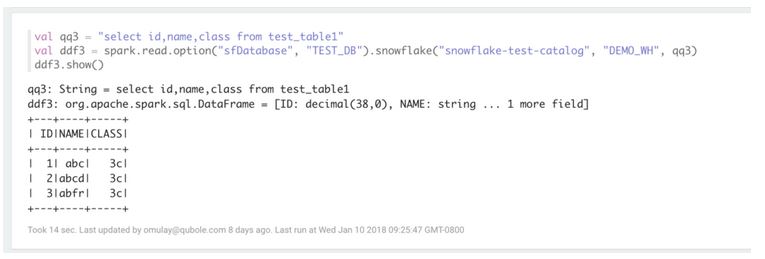
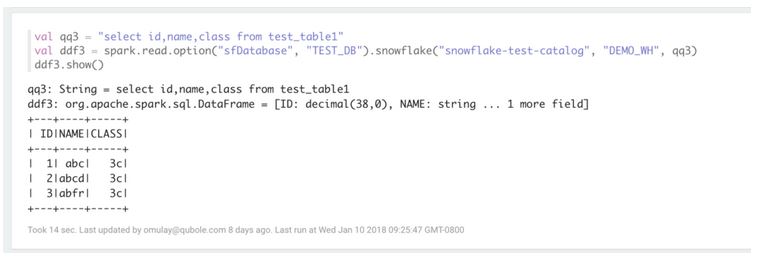
Un exemple de code Scala permettant de lire des données sur le datawarehouse à travers l’API Dataframe. (source : Qubole)
Disponible sur l’édition Enterprise de Qubole Data Service
La version bêta de cette intégration a été notamment testée par l’éditeur ReturnPatch, spécialisé dans la gestion de campagnes marketing d’e-mails. « Nous avons pu tirer parti des capacités de Spark en matière d’algorithmes de machine learning en utilisant les données résidant sur le datawarehouse de Snowflake, ce qui nous a permis d’accélérer nettement les temps de réalisation et de mise en œuvre des modèles, tout en continuant à effectuer des enregistrements et des requêtes sur Snowflake », explique dans un communiqué Anna Sheets, responsable Data Science et Analytics chez ReturnPath qui indique aussi avoir accéléré les temps de préparation des données. Cette intégration entre les deux services cloud est disponible à travers une évolution de l’édition Enterprise de l’offre Data Service de Qubole.